Publications
For a more complete list, see Google scholar.
*Equal contribution.
2025
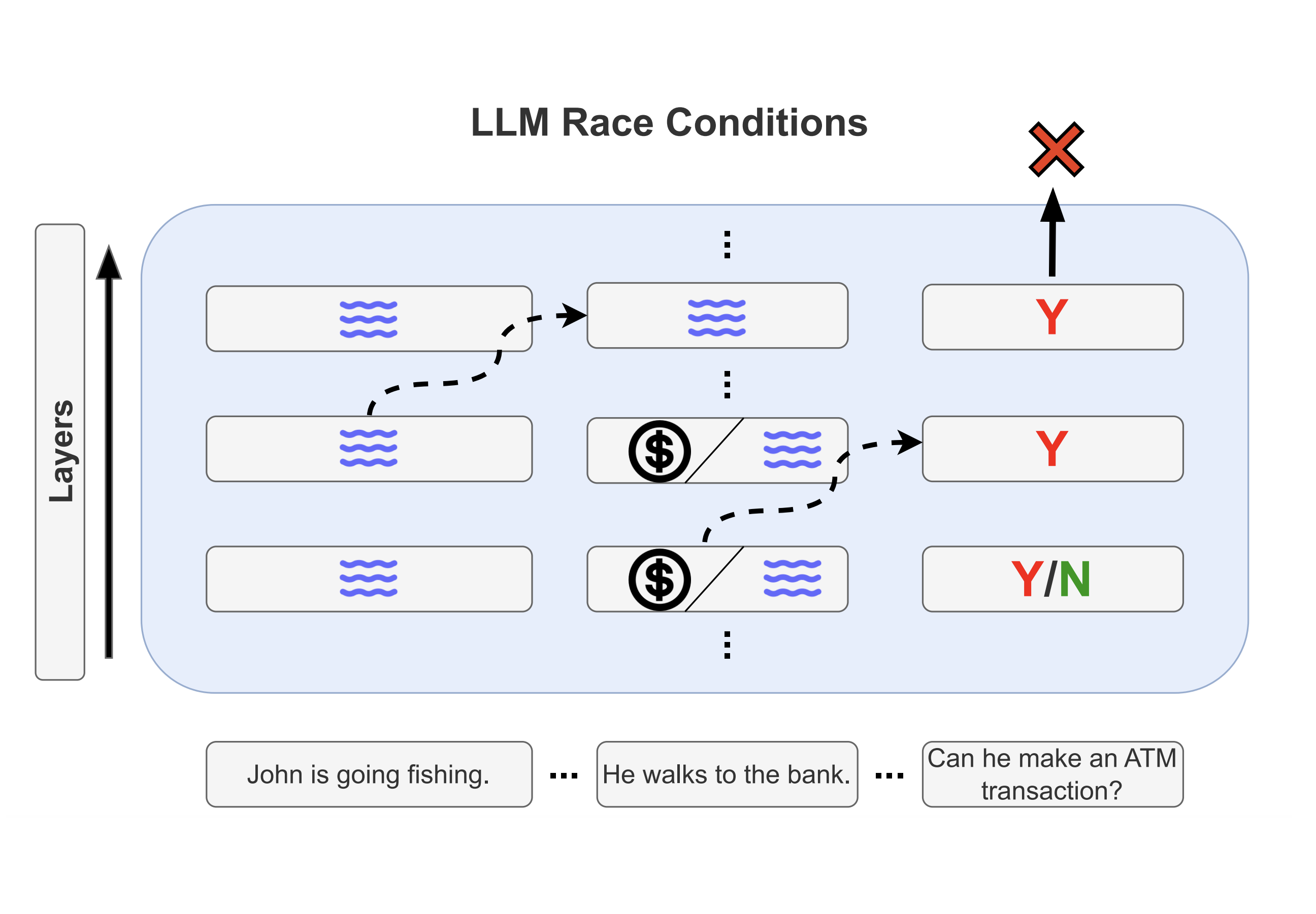 Racing Thoughts: Explaining Large Language Model Contextualization ErrorsMichael Lepori , Michael Mozer , and Asma GhandehariounAnnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2025(Oral)
Racing Thoughts: Explaining Large Language Model Contextualization ErrorsMichael Lepori , Michael Mozer , and Asma GhandehariounAnnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2025(Oral)The profound success of transformer-based language models can largely be attributed to their ability to integrate relevant contextual information from an input sequence in order to generate a response or complete a task. However, we know very little about the algorithms that a model employs to implement this capability, nor do we understand their failure modes. For example, given the prompt "John is going fishing, so he walks over to the bank. Can he make an ATM transaction?", a model may incorrectly respond "Yes" if it has not properly contextualized "bank" as a geographical feature, rather than a financial institution. We propose the LLM Race Conditions Hypothesis as an explanation of contextualization errors of this form. This hypothesis identifies dependencies between tokens (e.g., "bank" must be properly contextualized before the final token, "?", integrates information from "bank"), and claims that contextualization errors are a result of violating these dependencies. Using a variety of techniques from mechanistic intepretability, we provide correlational and causal evidence in support of the hypothesis, and suggest inference-time interventions to address it.
@article{lepori2025racing, title = {Racing Thoughts: Explaining Large Language Model Contextualization Errors}, author = {Lepori, Michael and Mozer, Michael and Ghandeharioun, Asma}, year = {2025}, journal = {Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)}, }

2024
 Who’s asking? User personas and the mechanics of latent misalignmentAdvances in Neural Information Processing Systems (NeurIPS), 2024(Spotlight)
Who’s asking? User personas and the mechanics of latent misalignmentAdvances in Neural Information Processing Systems (NeurIPS), 2024(Spotlight)Studies show that safety-tuned models may nevertheless divulge harmful information. In this work, we show that whether they do so depends significantly on who they are talking to, which we refer to as user persona. In fact, we find manipulating user persona to be more effective for eliciting harmful content than certain more direct attempts to control model refusal. We study both natural language prompting and activation steering as intervention methods and show that activation steering is significantly more effective at bypassing safety filters.We shed light on the mechanics of this phenomenon by showing that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. We also show we can predict a persona’s effect on refusal given only the geometry of its steering vector. Finally, we show that certain user personas induce the model to form more charitable interpretations of otherwise dangerous queries.
@article{ghandeharioun2024persona, title = {Who's asking? User personas and the mechanics of latent misalignment}, author = {}, year = {2024}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, }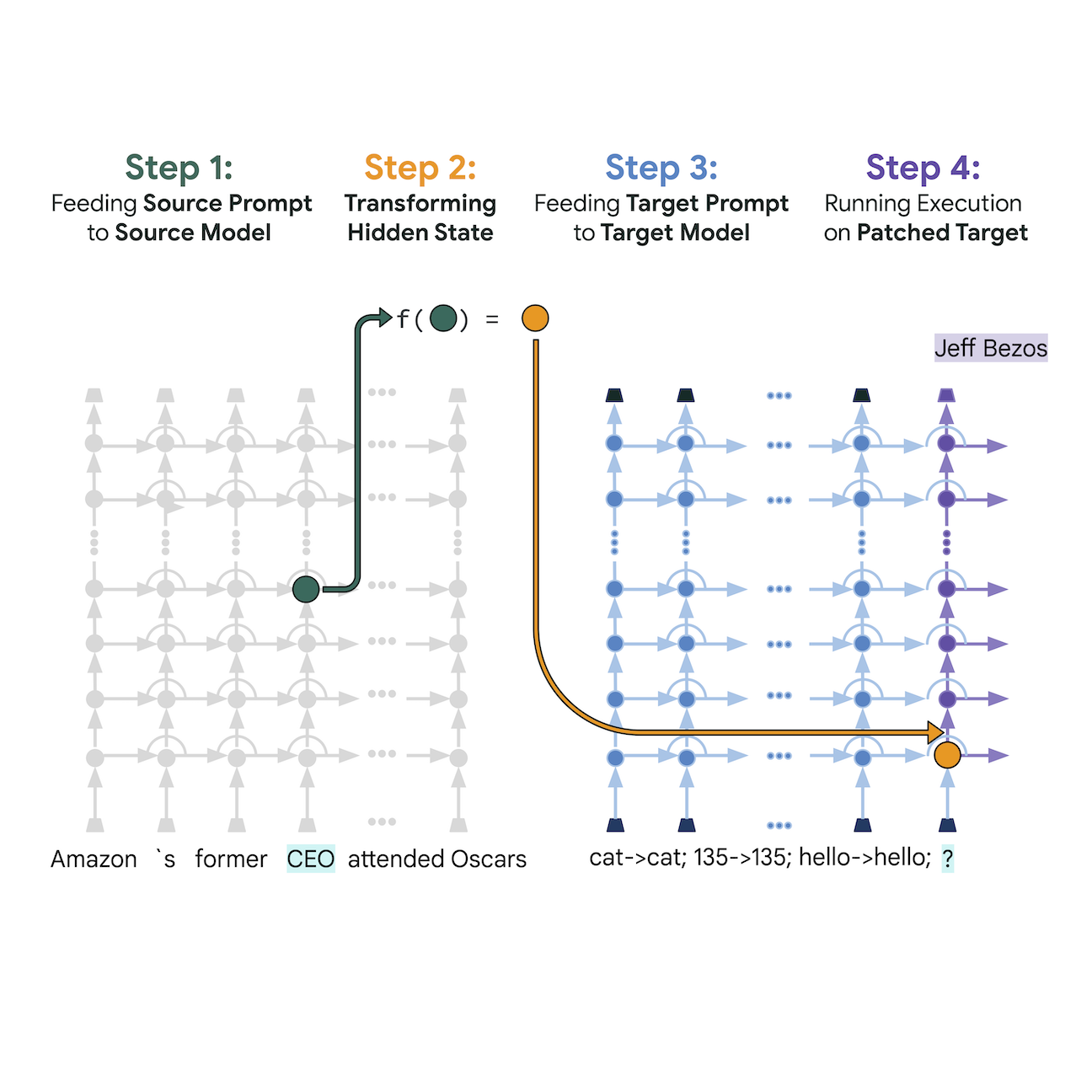 Patchscopes: A unifying framework for inspecting hidden representations of language modelsAsma Ghandeharioun*, Avi Caciularu* , Adam Pearce , Lucas Dixon , and Mor GevaInternational Conference on Machine Learning (ICML), 2024
Patchscopes: A unifying framework for inspecting hidden representations of language modelsAsma Ghandeharioun*, Avi Caciularu* , Adam Pearce , Lucas Dixon , and Mor GevaInternational Conference on Machine Learning (ICML), 2024Understanding the internal representations of large language models (LLMs) can help explain models’ behavior and verify their alignment with human values. Given the capabilities of LLMs in generating human-understandable text, we propose leveraging the model itself to explain its internal representations in natural language. We introduce a framework called Patchscopes and show how it can be used to answer a wide range of questions about an LLM’s computation. We show that many prior interpretability methods based on projecting representations into the vocabulary space and intervening on the LLM computation can be viewed as instances of this framework. Moreover, several of their shortcomings such as failure in inspecting early layers or lack of expressivity can be mitigated by Patchscopes. Beyond unifying prior inspection techniques, Patchscopes also opens up new possibilities such as using a more capable model to explain the representations of a smaller model, and self-correction in multihop reasoning, even outperforming chain-of-thought prompting.
@article{ghandeharioun2024patchscopes, title = {Patchscopes: A unifying framework for inspecting hidden representations of language models}, author = {Ghandeharioun*, Asma and Caciularu*, Avi and Pearce, Adam and Dixon, Lucas and Geva, Mor}, year = {2024}, journal = {International Conference on Machine Learning (ICML)}, } When Can Transformers Count to n?Gilad Yehudai , Haim Kaplan , Asma Ghandeharioun, Mor Geva , and Amir Globersonarxiv, 2024
When Can Transformers Count to n?Gilad Yehudai , Haim Kaplan , Asma Ghandeharioun, Mor Geva , and Amir Globersonarxiv, 2024Large language models based on the transformer architectures can solve highly complex tasks. But are there simple tasks that such models cannot solve? Here we focus on very simple counting tasks, that involve counting how many times a token in the vocabulary have appeared in a string. We show that if the dimension of the transformer state is linear in the context length, this task can be solved. However, the solution we propose does not scale beyond this limit, and we provide theoretical arguments for why it is likely impossible for a size limited transformer to implement this task. Our empirical results demonstrate the same phase-transition in performance, as anticipated by the theoretical argument. Our results demonstrate the importance of understanding how transformers can solve simple tasks.
@article{yehudai2024count, title = {When Can Transformers Count to n?}, author = {Yehudai, Gilad and Kaplan, Haim and Ghandeharioun, Asma and Geva, Mor and Globerson, Amir}, year = {2024}, journal = {arxiv}, }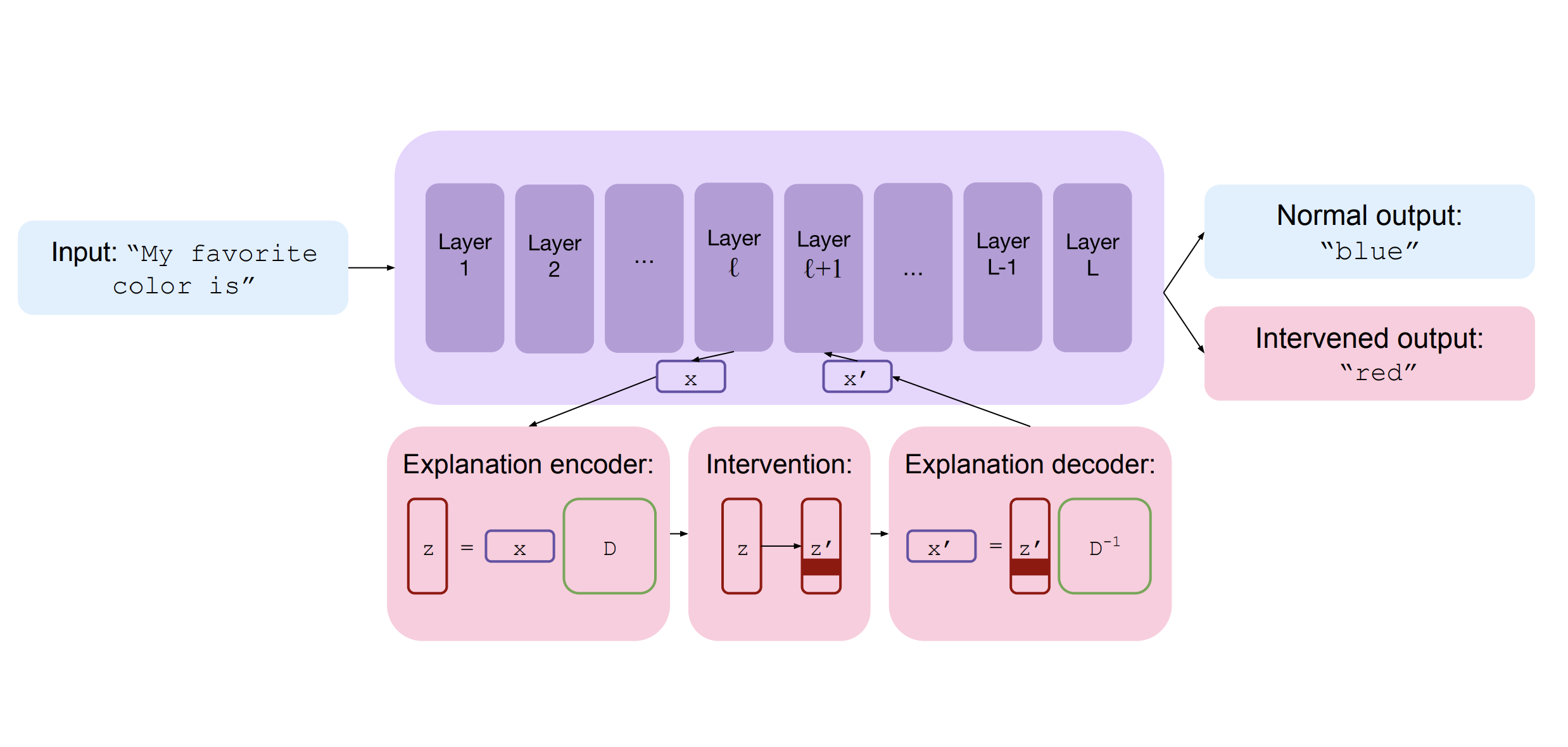 Towards unifying interpretability and control: Evaluation via interventionUsha Bhalla , Suraj Srinivas , Asma Ghandeharioun, and Himabindu Lakkarajuarxiv, 2024
Towards unifying interpretability and control: Evaluation via interventionUsha Bhalla , Suraj Srinivas , Asma Ghandeharioun, and Himabindu Lakkarajuarxiv, 2024With the growing complexity and capability of large language models, a need to understand model reasoning has emerged, often motivated by an underlying goal of controlling and aligning models. While numerous interpretability and steering methods have been proposed as solutions, they are typically designed either for understanding or for control, seldom addressing both. Additionally, the lack of standardized applications, motivations, and evaluation metrics makes it difficult to assess methods’ practical utility and efficacy. To address the aforementioned issues, we argue that intervention is a fundamental goal of interpretability and introduce success criteria to evaluate how well methods can control model behavior through interventions. To evaluate existing methods for this ability, we unify and extend four popular interpretability methods-sparse autoencoders, logit lens, tuned lens, and probing-into an abstract encoder-decoder framework, enabling interventions on interpretable features that can be mapped back to latent representations to control model outputs. We introduce two new evaluation metrics: intervention success rate and coherence-intervention tradeoff, designed to measure the accuracy of explanations and their utility in controlling model behavior. Our findings reveal that (1) while current methods allow for intervention, their effectiveness is inconsistent across features and models, (2) lens-based methods outperform SAEs and probes in achieving simple, concrete interventions, and (3) mechanistic interventions often compromise model coherence, underperforming simpler alternatives, such as prompting, and highlighting a critical shortcoming of current interpretability approaches in applications requiring control.
@article{bhalla2024unifying, title = {Towards unifying interpretability and control: Evaluation via intervention}, author = {Bhalla, Usha and Srinivas, Suraj and Ghandeharioun, Asma and Lakkaraju, Himabindu}, year = {2024}, journal = {arxiv}, }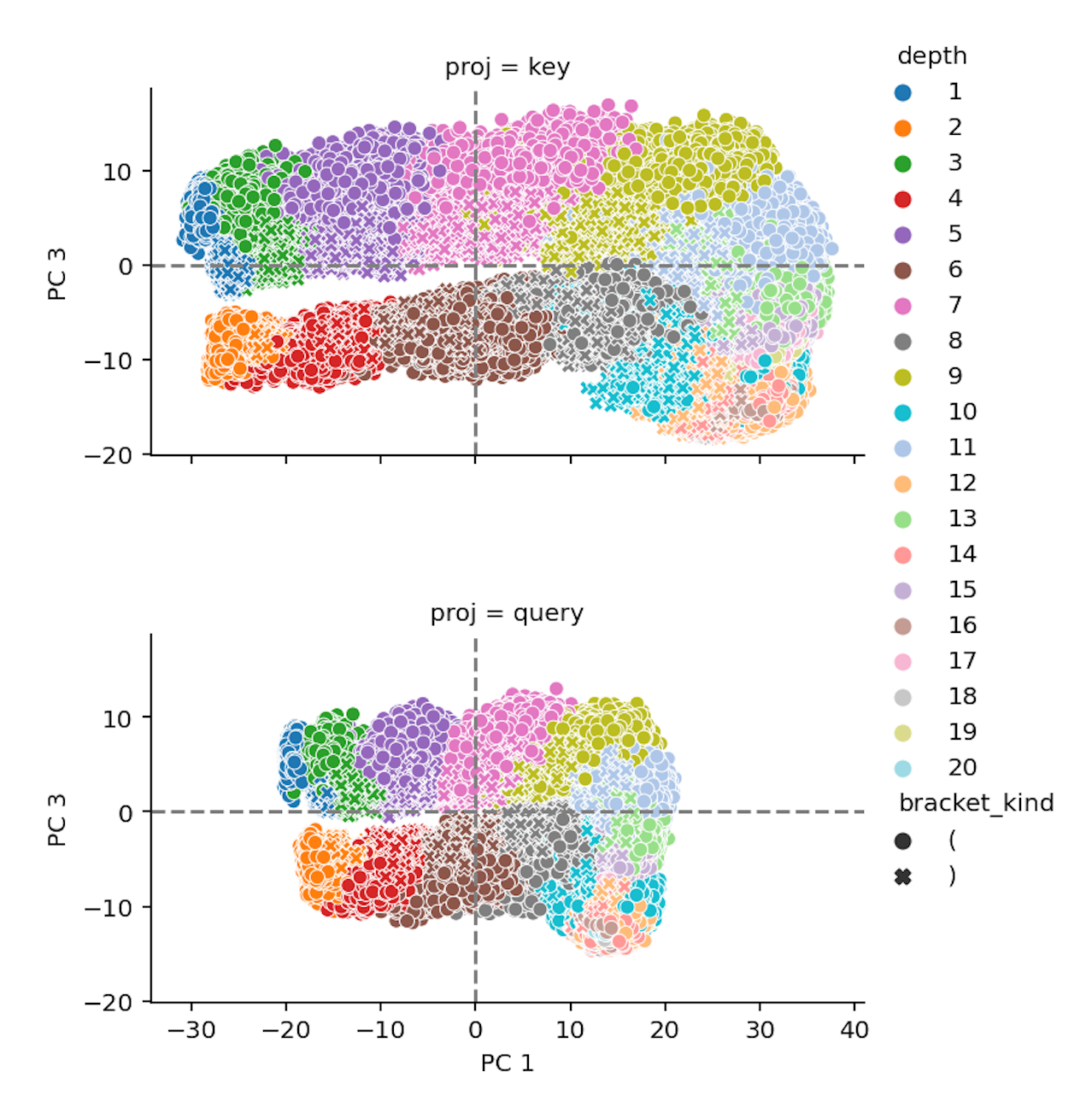 Interpretability illusions in the generalization of simplified modelsDan Friedman , Andrew Kyle Lampinen , Lucas Dixon , Danqi Chen , and Asma GhandehariounInternational Conference on Machine Learning (ICML), 2024
Interpretability illusions in the generalization of simplified modelsDan Friedman , Andrew Kyle Lampinen , Lucas Dixon , Danqi Chen , and Asma GhandehariounInternational Conference on Machine Learning (ICML), 2024A common method to study deep learning systems is to create simplified representations—for example, using singular value decomposition to visualize the model’s hidden states in a lower dimensional space. This approach assumes that the simplified model is faithful to the original model. Here, we illustrate an important caveat to this assumption: even if a simplified representation of the model can accurately approximate the original model on the training set, it may fail to match its behavior out of distribution; the understanding developed from simplified representations may be an illusion. We illustrate this by training Transformer models on controlled datasets with systematic generalization splits, focusing on the Dyck balanced-parenthesis languages. We simplify these models using tools like dimensionality-reduction and clustering, and find clear patterns in the resulting representations. We then explicitly test how these simplified proxy models match the original models behavior on various out-of-distribution test sets. Generally, the simplified proxies are less faithful out of distribution. For example, in cases where the original model generalizes to novel structures or deeper depths, the simplified model may fail to generalize, or may generalize too well. We then show the generality of these results: even model simplifications that do not directly use data can be less faithful out of distribution, and other tasks can also yield generalization gaps. Our experiments raise questions about the extent to which mechanistic interpretations derived using tools like SVD can reliably predict what a model will do in novel situations.
@article{friedman2024interpretability, title = {Interpretability illusions in the generalization of simplified models}, author = {Friedman, Dan and Lampinen, Andrew Kyle and Dixon, Lucas and Chen, Danqi and Ghandeharioun, Asma}, journal = {International Conference on Machine Learning (ICML)}, year = {2024}, }





2023
 Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language modelsPeter Hase , Mohit Bansal , Been Kim , and Asma GhandehariounAdvances in Neural Information Processing Systems (NeurIPS), 2023(Spotlight)
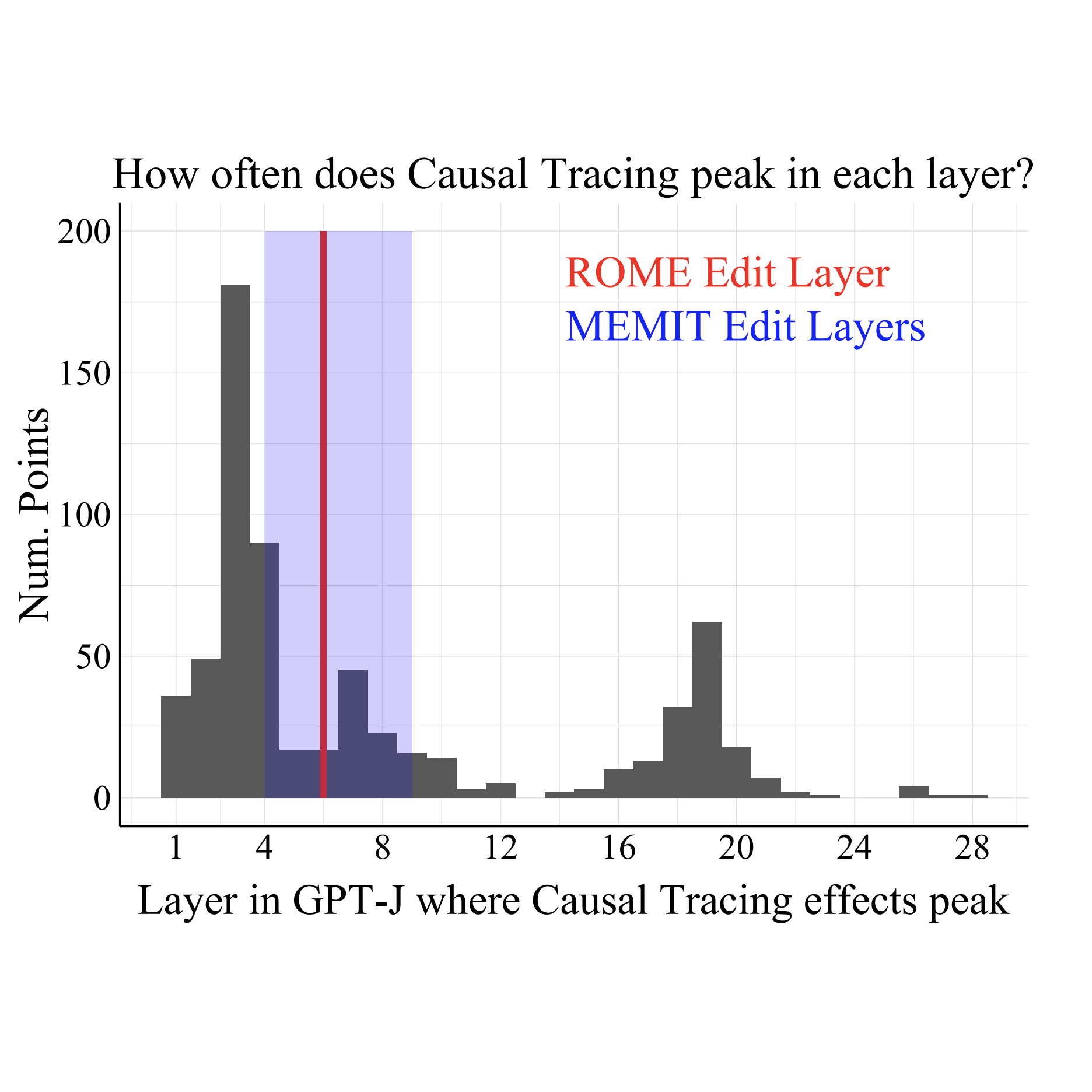
Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language modelsPeter Hase , Mohit Bansal , Been Kim , and Asma GhandehariounAdvances in Neural Information Processing Systems (NeurIPS), 2023(Spotlight)Language models learn a great quantity of factual information during pretraining, and recent work localizes this information to specific model weights like mid-layer MLP weights. In this paper, we find that we can change how a fact is stored in a model by editing weights that are in a different location than where existing methods suggest that the fact is stored. This is surprising because we would expect that localizing facts to specific model parameters would tell us where to manipulate knowledge in models, and this assumption has motivated past work on model editing methods. Specifically, we show that localization conclusions from representation denoising (also known as Causal Tracing) do not provide any insight into which model MLP layer would be best to edit in order to override an existing stored fact with a new one. This finding raises questions about how past work relies on Causal Tracing to select which model layers to edit. Next, we consider several variants of the editing problem, including erasing and amplifying facts. For one of our editing problems, editing performance does relate to localization results from representation denoising, but we find that which layer we edit is a far better predictor of performance. Our results suggest, counterintuitively, that better mechanistic understanding of how pretrained language models work may not always translate to insights about how to best change their behavior.
@article{hase2023localization, title = {Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models}, author = {Hase, Peter and Bansal, Mohit and Kim, Been and Ghandeharioun, Asma}, journal = {Advances in Neural Information Processing Systems (NeurIPS)}, volume = {36}, year = {2023}, }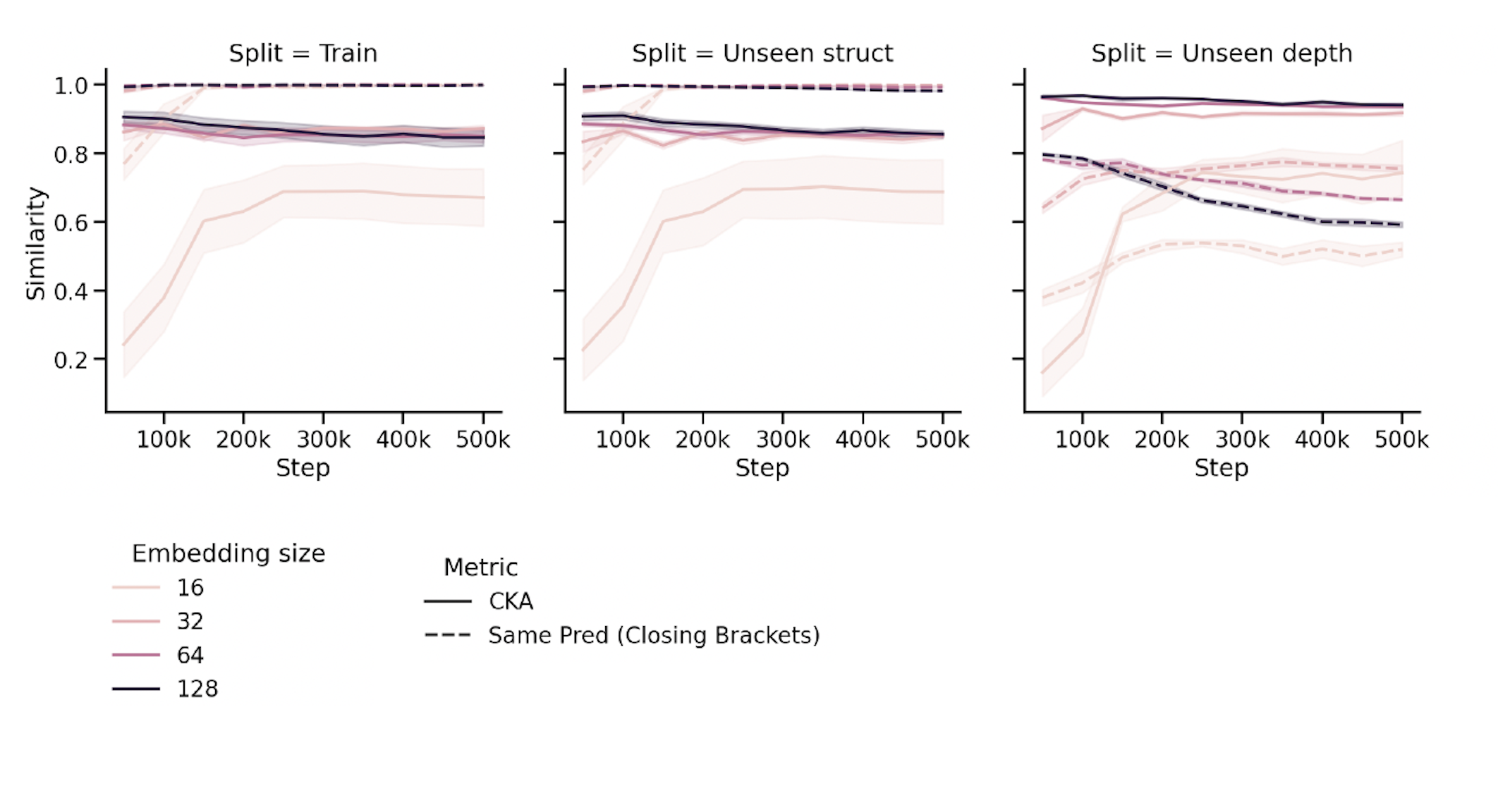 Comparing Representational and Functional Similarity in Small Transformer Language ModelsDan Friedman , Andrew Kyle Lampinen , Lucas Dixon , Danqi Chen , and Asma GhandehariounIn UniReps: the First Workshop on Unifying Representations in Neural Models. (NeurIPS-W) , 2023(Oral)
Comparing Representational and Functional Similarity in Small Transformer Language ModelsDan Friedman , Andrew Kyle Lampinen , Lucas Dixon , Danqi Chen , and Asma GhandehariounIn UniReps: the First Workshop on Unifying Representations in Neural Models. (NeurIPS-W) , 2023(Oral)In many situations, it would be helpful to be able to characterize the solution learned by a neural network, including for answering scientific questions (e.g. how do architecture changes affect generalization) and addressing practical concerns (e.g. auditing for potentially unsafe behavior). One approach is to try to understand these models by studying the representations that they learn—for example, comparing whether two networks learn similar representations. However, it is not always clear how much representation-level analyses can tell us about how a model makes predictions. In this work, we explore this question in the context of small Transformer language models, which we train on a synthetic, hierarchical language task. We train models with different sizes and random initializations, evaluating performance over the course of training and on a variety of systematic generalization splits. We find that existing methods for measuring representation similarity are not always correlated with behavioral metrics—i.e. models with similar representations do not always make similar predictions—and the results vary depending on the choice of representation. Our results highlight the importance of understanding representations in terms of the role they play in the neural algorithm.
@inproceedings{friedman2023comparing, title = {Comparing Representational and Functional Similarity in Small Transformer Language Models}, author = {Friedman, Dan and Lampinen, Andrew Kyle and Dixon, Lucas and Chen, Danqi and Ghandeharioun, Asma}, booktitle = {UniReps: the First Workshop on Unifying Representations in Neural Models. (NeurIPS-W)}, year = {2023}, }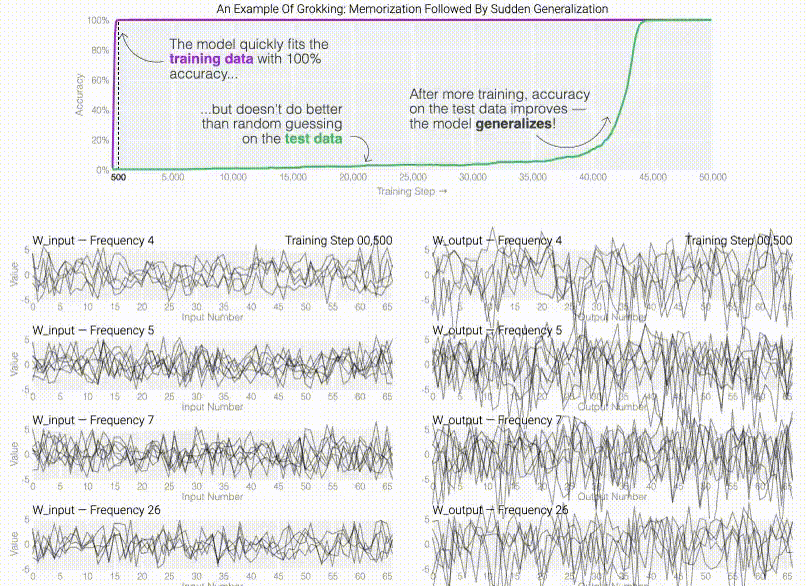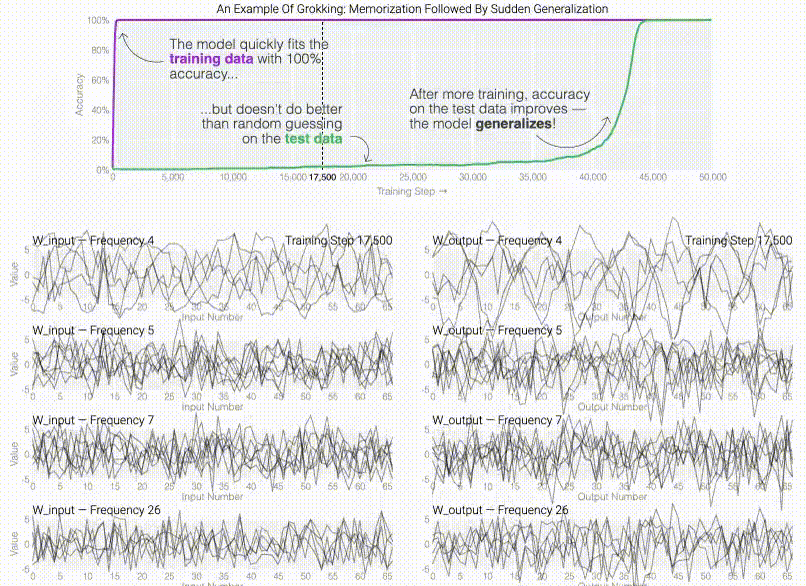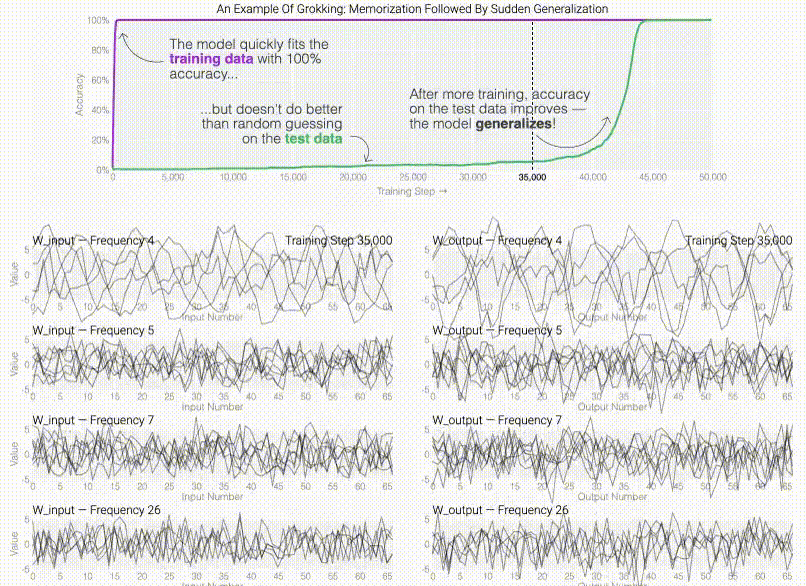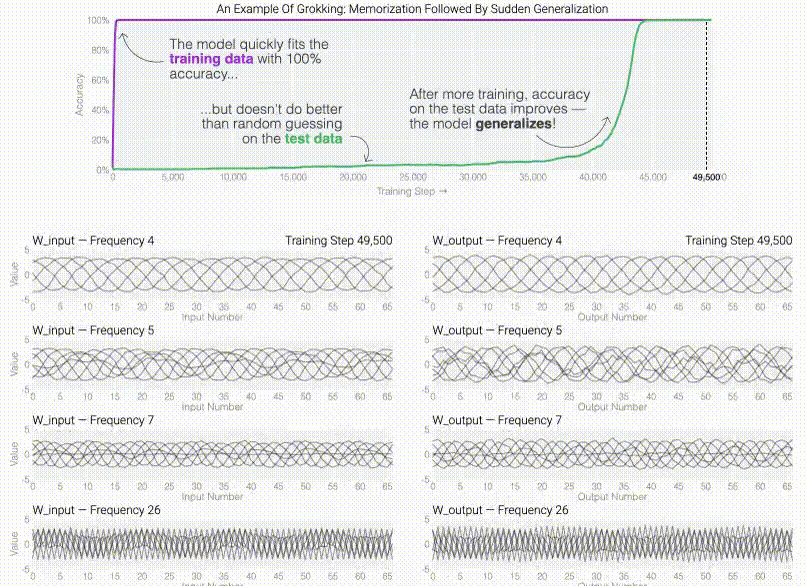 Do machine learning models memorize or generalizeAdam Pearce , Asma Ghandeharioun, Nada Hussein , Nithum Thain , Martin Wattenberg , and Lucas DixonIn IEEE VISxAI , 2023(Best paper)
Do machine learning models memorize or generalizeAdam Pearce , Asma Ghandeharioun, Nada Hussein , Nithum Thain , Martin Wattenberg , and Lucas DixonIn IEEE VISxAI , 2023(Best paper)@inproceedings{pearce2023machine, title = {Do machine learning models memorize or generalize}, author = {Pearce, Adam and Ghandeharioun, Asma and Hussein, Nada and Thain, Nithum and Wattenberg, Martin and Dixon, Lucas}, booktitle = {IEEE VISxAI}, year = {2023}, }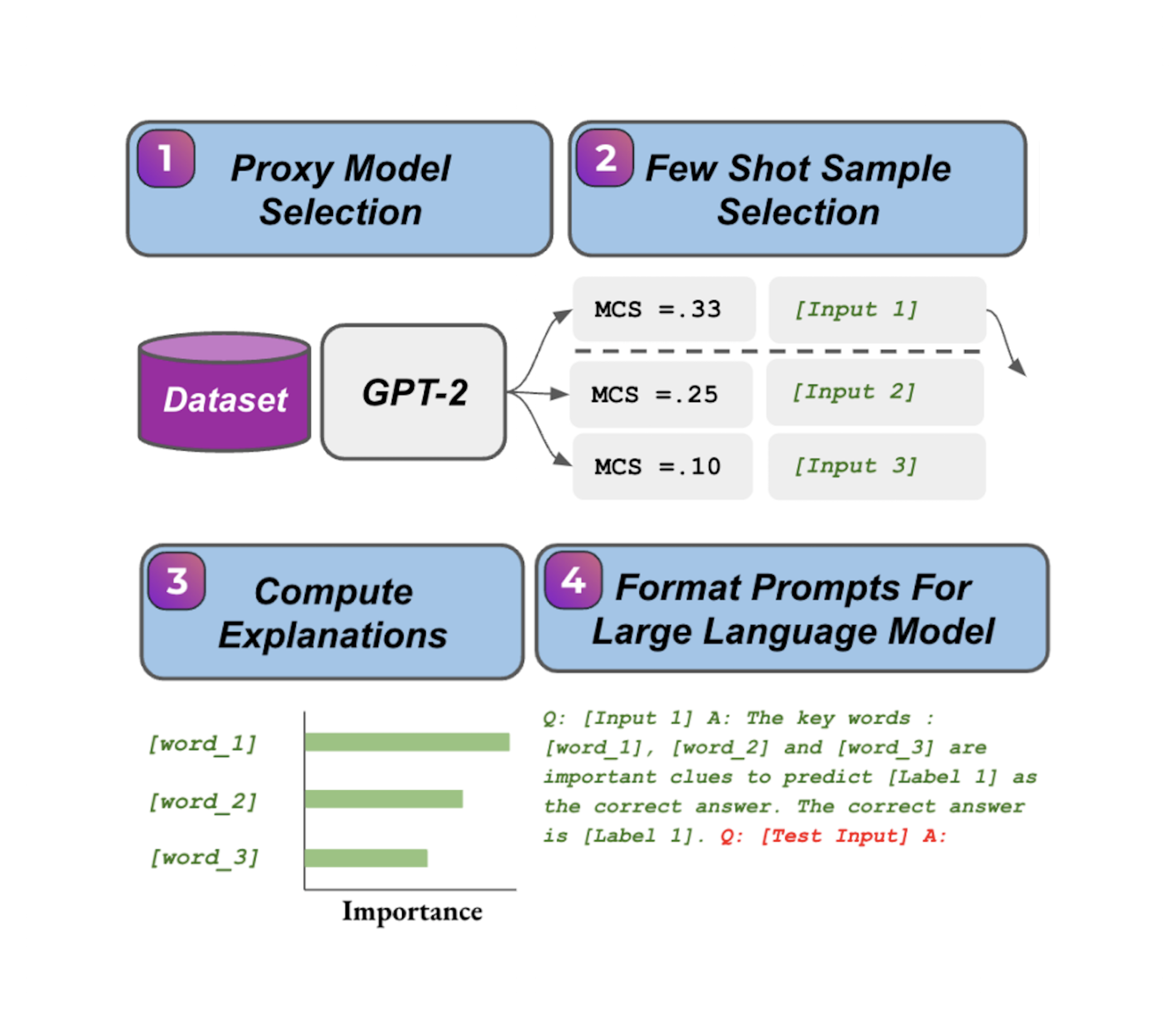 Post Hoc Explanations of Language Models Can Improve Language ModelsSatyapriya Krishna , Jiaqi Ma , Dylan Slack , Asma Ghandeharioun, Sameer Singh , and Himabindu LakkarajuIn Advances in Neural Information Processing Systems (NeurIPS) , 2023
Post Hoc Explanations of Language Models Can Improve Language ModelsSatyapriya Krishna , Jiaqi Ma , Dylan Slack , Asma Ghandeharioun, Sameer Singh , and Himabindu LakkarajuIn Advances in Neural Information Processing Systems (NeurIPS) , 2023Large Language Models (LLMs) have demonstrated remarkable capabilities in performing complex tasks. Moreover, recent research has shown that incorporating human-annotated rationales (e.g., Chain-of-Thought prompting) during in-context learning can significantly enhance the performance of these models, particularly on tasks that require reasoning capabilities. However, incorporating such rationales poses challenges in terms of scalability as this requires a high degree of human involvement. In this work, we present a novel framework, Amplifying Model Performance by Leveraging In-Context Learning with Post Hoc Explanations (AMPLIFY), which addresses the aforementioned challenges by automating the process of rationale generation. To this end, we leverage post hoc explanation methods which output attribution scores (explanations) capturing the influence of each of the input features on model predictions. More specifically, we construct automated natural language rationales that embed insights from post hoc explanations to provide corrective signals to LLMs. Extensive experimentation with real-world datasets demonstrates that our framework, AMPLIFY, leads to prediction accuracy improvements of about 10-25% over a wide range of tasks, including those where prior approaches which rely on human-annotated rationales such as Chain-of-Thought prompting fall short. Our work makes one of the first attempts at highlighting the potential of post hoc explanations as valuable tools for enhancing the effectiveness of LLMs. Furthermore, we conduct additional empirical analyses and ablation studies to demonstrate the impact of each of the components of AMPLIFY, which, in turn, lead to critical insights for refining in context learning.
@inproceedings{krishna2023post, title = {Post Hoc Explanations of Language Models Can Improve Language Models}, author = {Krishna, Satyapriya and Ma, Jiaqi and Slack, Dylan and Ghandeharioun, Asma and Singh, Sameer and Lakkaraju, Himabindu}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2023}, }




2021
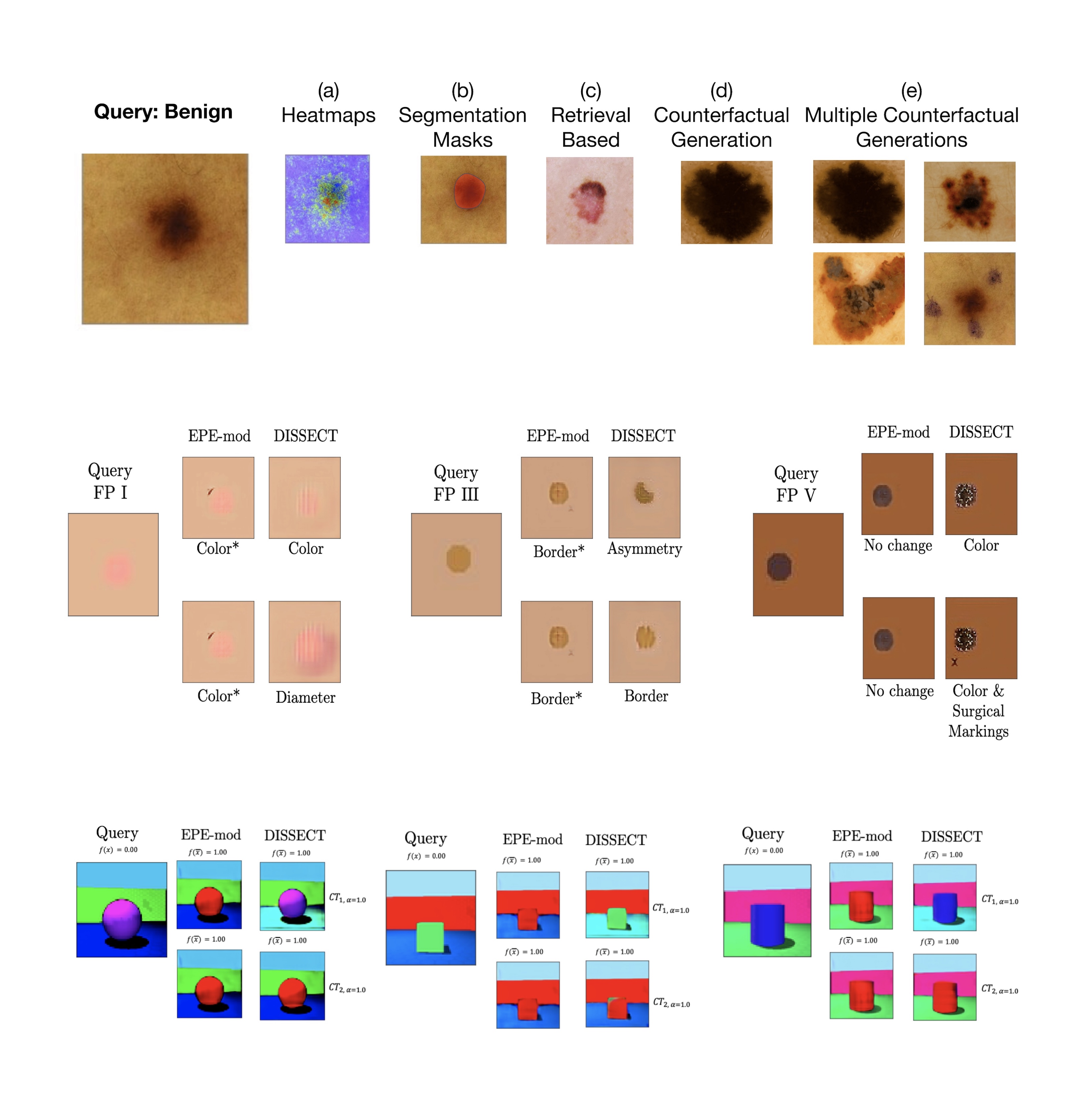 DISSECT: Disentangled simultaneous explanations via concept traversalsAsma Ghandeharioun, Been Kim , Chun-Liang Li , Brendan Jou , Brian Eoff , and Rosalind W PicardIn International Conference on Learning Representations (ICLR) , 2021
DISSECT: Disentangled simultaneous explanations via concept traversalsAsma Ghandeharioun, Been Kim , Chun-Liang Li , Brendan Jou , Brian Eoff , and Rosalind W PicardIn International Conference on Learning Representations (ICLR) , 2021Explaining deep learning model inferences is a promising venue for scientific understanding, improving safety, uncovering hidden biases, evaluating fairness, and beyond, as argued by many scholars. One of the principal benefits of counterfactual explanations is allowing users to explore "what-if" scenarios through what does not and cannot exist in the data, a quality that many other forms of explanation such as heatmaps and influence functions are inherently incapable of doing. However, most previous work on generative explainability cannot disentangle important concepts effectively, produces unrealistic examples, or fails to retain relevant information. We propose a novel approach, DISSECT, that jointly trains a generator, a discriminator, and a concept disentangler to overcome such challenges using little supervision. DISSECT generates Concept Traversals (CTs), defined as a sequence of generated examples with increasing degrees of concepts that influence a classifier’s decision. By training a generative model from a classifier’s signal, DISSECT offers a way to discover a classifier’s inherent "notion" of distinct concepts automatically rather than rely on user-predefined concepts. We show that DISSECT produces CTs that (1) disentangle several concepts, (2) are influential to a classifier’s decision and are coupled to its reasoning due to joint training (3), are realistic, (4) preserve relevant information, and (5) are stable across similar inputs. We validate DISSECT on several challenging synthetic and realistic datasets where previous methods fall short of satisfying desirable criteria for interpretability and show that it performs consistently well. Finally, we present experiments showing applications of DISSECT for detecting potential biases of a classifier and identifying spurious artifacts that impact predictions.
@inproceedings{ghandeharioun2021dissect, title = {DISSECT: Disentangled simultaneous explanations via concept traversals}, author = {Ghandeharioun, Asma and Kim, Been and Li, Chun-Liang and Jou, Brendan and Eoff, Brian and Picard, Rosalind W}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2021}, }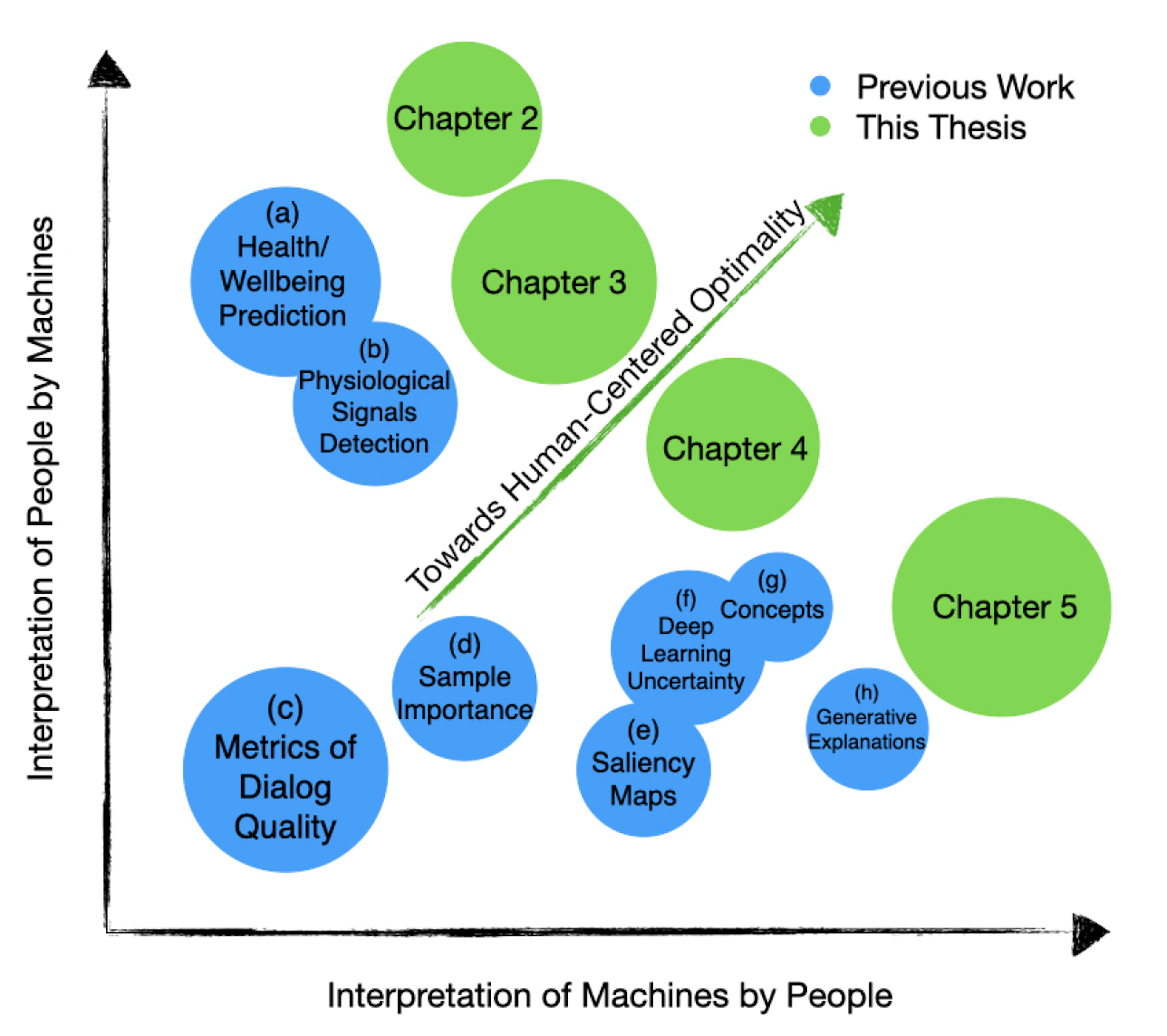 Towards Human-Centered Optimality CriteriaAsma GhandehariounMassachusetts Institute of Technology , 2021
Towards Human-Centered Optimality CriteriaAsma GhandehariounMassachusetts Institute of Technology , 2021Despite the transformational success of machine learning across various applications, examples of deployed models failing to recognize and support human-centered (HC) criteria are abundant. In this thesis, I conceptualize the space of human-machine collaboration with respect to two components: interpretation of people by machines and interpretation of machines by people. I develop several tools that make improvements along these axes. First, I develop a pipeline that predicts depressive symptoms rated by clinicians from real-world longitudinal data outperforming several baselines. Second, I introduce a novel, model-agnostic, and dataset-agnostic method to approximate interactive human evaluation in open-domain dialog through self-play that is more strongly correlated with human evaluations than other automated metrics commonly used today. While dialog quality evaluation metrics predominantly use word-level overlap or distance metrics based on embedding resemblance to each turn of the conversation, I show the significance of taking into account the conversation’s trajectory and using proxies such as sentiment, semantics, and user engagement that are psychologically motivated. Third, I demonstrate an uncertainty measurement technique that helps disambiguate annotator disagreement and data bias. I show that this characterization also improves model performance. Finally, I present a novel method that allows humans to investigate a predictor’s decision-making process to gain better insight into how it works. The method jointly trains a generator, a discriminator, and a concept disentangler, allowing the human to ask "what-if" questions. I evaluate it on several challenging synthetic and realistic datasets where previous methods fall short of satisfying desirable criteria for interpretability and show that our method performs consistently well across all. I discuss its applications to detect potential biases of a classifier and identify spurious artifacts that impact predictions using simulated experiments. Together, these novel techniques and insights provide a more comprehensive interpretation of people by machines and more powerful tools for interpretation of machines by people that can move us closer to HC optimality.
@phdthesis{ghandeharioun2021towards, title = {Towards Human-Centered Optimality Criteria}, author = {Ghandeharioun, Asma}, year = {2021}, school = {Massachusetts Institute of Technology}, }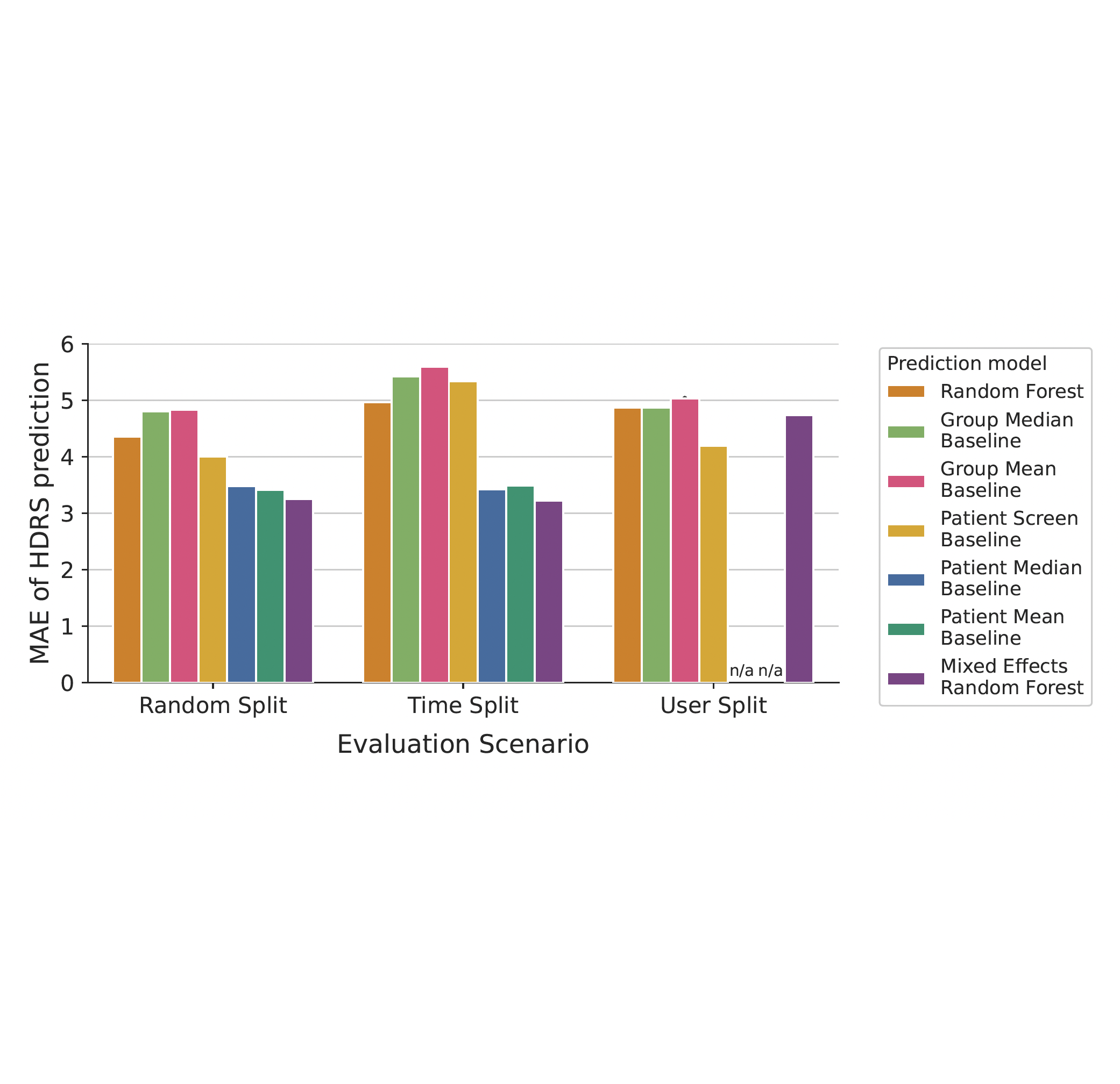 Mixed effects random forests for personalised predictions of clinical depression severityRobert A Lewis , Asma Ghandeharioun, Szymon Fedor , Paola Pedrelli , Rosalind W Picard , and David MischoulonIn Workshop on Computational Approaches to Mental Health @ ICML , 2021
Mixed effects random forests for personalised predictions of clinical depression severityRobert A Lewis , Asma Ghandeharioun, Szymon Fedor , Paola Pedrelli , Rosalind W Picard , and David MischoulonIn Workshop on Computational Approaches to Mental Health @ ICML , 2021This work demonstrates how mixed effects random forests enable accurate predictions of depression severity using multimodal physiological and digital activity data collected from an 8-week study involving 31 patients with major depressive disorder. We show that mixed effects random forests outperform standard random forests and personal average baselines when predicting clinical Hamilton Depression Rating Scale scores (HDRS_17). Compared to the latter baseline, accuracy is significantly improved for each patient by an average of 0.199-0.276 in terms of mean absolute error (p<0.05). This is noteworthy as these simple baselines frequently outperform machine learning methods in mental health prediction tasks. We suggest that this improved performance results from the ability of the mixed effects random forest to personalise model parameters to individuals in the dataset. However, we find that these improvements pertain exclusively to scenarios where labelled patient data are available to the model at training time. Investigating methods that improve accuracy when generalising to new patients is left as important future work.



2020
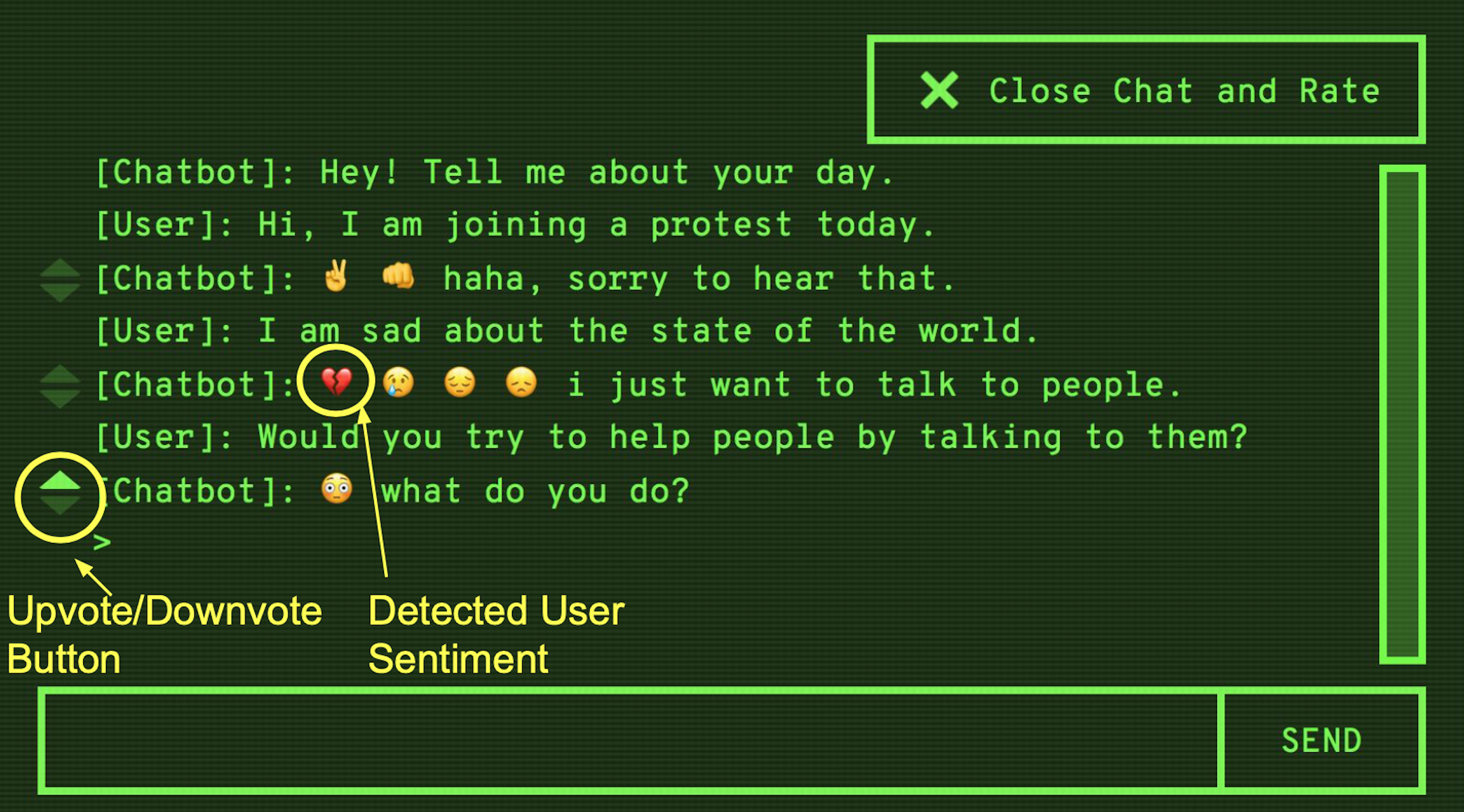 Human-centric dialog training via offline reinforcement learningNatasha Jaques* , Judy Hanwen Shen* , Asma Ghandeharioun, Craig Ferguson , Agata Lapedriza , Noah Jones , Shixiang Shane Gu , and Rosalind PicardIn Empirical Methods in Natural Language Processing (EMNLP) , 2020(Oral)
Human-centric dialog training via offline reinforcement learningNatasha Jaques* , Judy Hanwen Shen* , Asma Ghandeharioun, Craig Ferguson , Agata Lapedriza , Noah Jones , Shixiang Shane Gu , and Rosalind PicardIn Empirical Methods in Natural Language Processing (EMNLP) , 2020(Oral)How can we train a dialog model to produce better conversations by learning from human feedback, without the risk of humans teaching it harmful chat behaviors? We start by hosting models online, and gather human feedback from real-time, open-ended conversations, which we then use to train and improve the models using offline reinforcement learning (RL). We identify implicit conversational cues including language similarity, elicitation of laughter, sentiment, and more, which indicate positive human feedback, and embed these in multiple reward functions. A well-known challenge is that learning an RL policy in an offline setting usually fails due to the lack of ability to explore and the tendency to make over-optimistic estimates of future reward. These problems become even harder when using RL for language models, which can easily have a 20,000 action vocabulary and many possible reward functions. We solve the challenge by developing a novel class of offline RL algorithms. These algorithms use KL-control to penalize divergence from a pre-trained prior language model, and use a new strategy to make the algorithm pessimistic, instead of optimistic, in the face of uncertainty. We test the resulting dialog model with ratings from 80 users in an open-domain setting and find it achieves significant improvements over existing deep offline RL approaches. The novel offline RL method is viable for improving any existing generative dialog model using a static dataset of human feedback.
@inproceedings{jaques2020human, title = {Human-centric dialog training via offline reinforcement learning}, author = {Jaques*, Natasha and Shen*, Judy Hanwen and Ghandeharioun, Asma and Ferguson, Craig and Lapedriza, Agata and Jones, Noah and Gu, Shixiang Shane and Picard, Rosalind}, booktitle = {Empirical Methods in Natural Language Processing (EMNLP)}, year = {2020}, }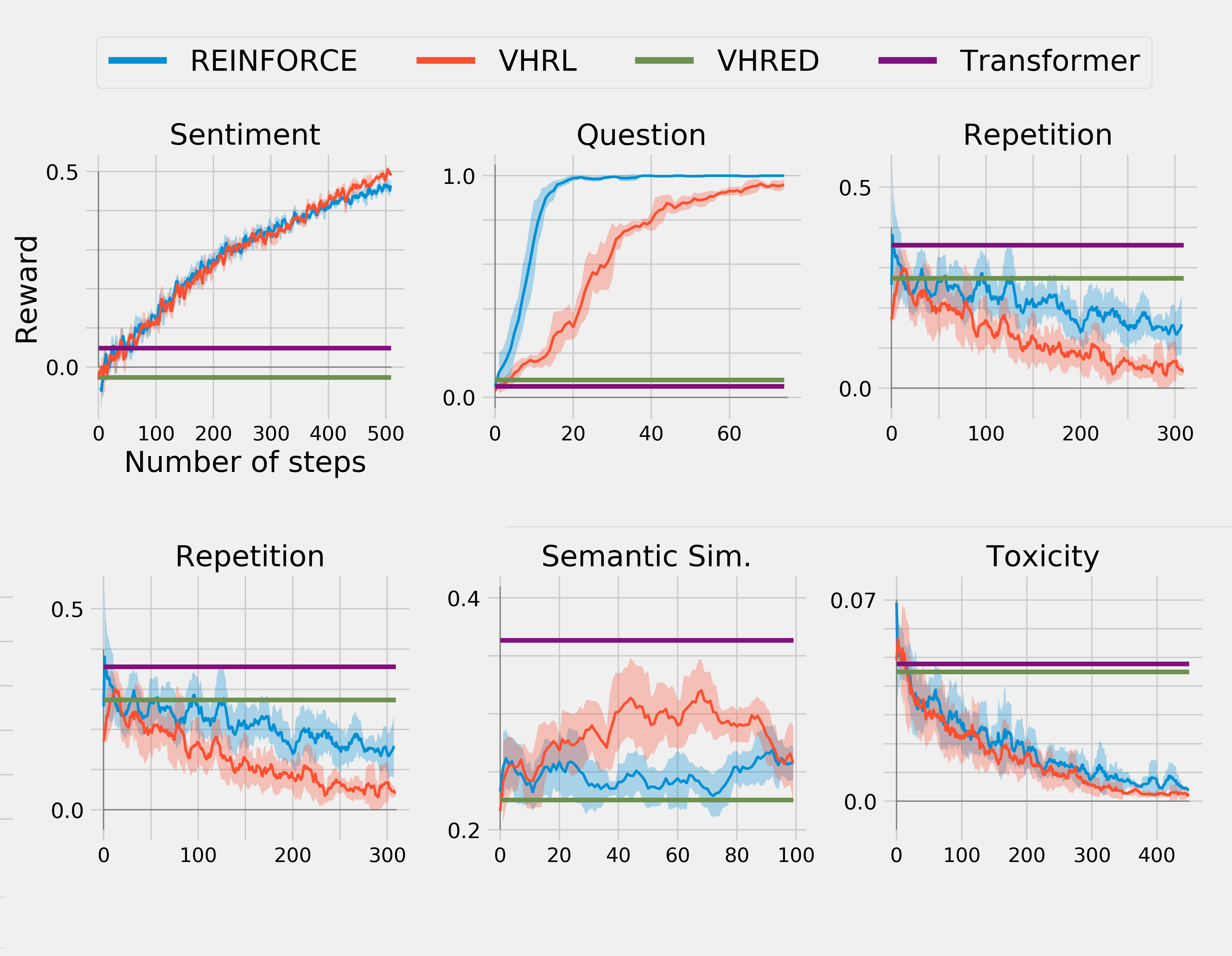 Hierarchical reinforcement learning for open-domain dialogAbdelrhman Saleh* , Natasha Jaques* , Asma Ghandeharioun, Judy Shen , and Rosalind W PicardIn Proceedings of the AAAI conference on artificial intelligence (AAAI) , 2020(Oral)
Hierarchical reinforcement learning for open-domain dialogAbdelrhman Saleh* , Natasha Jaques* , Asma Ghandeharioun, Judy Shen , and Rosalind W PicardIn Proceedings of the AAAI conference on artificial intelligence (AAAI) , 2020(Oral)Open-domain dialog generation is a challenging problem; maximum likelihood training can lead to repetitive outputs, models have difficulty tracking long-term conversational goals, and training on standard movie or online datasets may lead to the generation of inappropriate, biased, or offensive text. Reinforcement Learning (RL) is a powerful framework that could potentially address these issues, for example by allowing a dialog model to optimize for reducing toxicity and repetitiveness. However, previous approaches which apply RL to open-domain dialog generation do so at the word level, making it difficult for the model to learn proper credit assignment for long-term conversational rewards. In this paper, we propose a novel approach to hierarchical reinforcement learning, VHRL, which uses policy gradients to tune the utterance-level embedding of a variational sequence model. This hierarchical approach provides greater flexibility for learning long-term, conversational rewards. We use self-play and RL to optimize for a set of human-centered conversation metrics, and show that our approach provides significant improvements – in terms of both human evaluation and automatic metrics – over state-of-the-art dialog models, including Transformers.
@inproceedings{saleh2020hierarchical, title = {Hierarchical reinforcement learning for open-domain dialog}, author = {Saleh*, Abdelrhman and Jaques*, Natasha and Ghandeharioun, Asma and Shen, Judy and Picard, Rosalind W}, booktitle = {Proceedings of the AAAI conference on artificial intelligence (AAAI)}, volume = {34}, number = {05}, pages = {8741--8748}, year = {2020}, } Studying personalized just-in-time auditory breathing guides and potential safety implications during simulated drivingSebastian Zepf , Neska El Haouij , Jinmo Lee , Asma Ghandeharioun, Javier Hernandez , and Rosalind W PicardIn Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization , 2020
Studying personalized just-in-time auditory breathing guides and potential safety implications during simulated drivingSebastian Zepf , Neska El Haouij , Jinmo Lee , Asma Ghandeharioun, Javier Hernandez , and Rosalind W PicardIn Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization , 2020Driving can occupy a considerable part of our daily lives and is often associated with high levels of stress. Motivated by the effectiveness of controlled breathing, this work studies the potential use of breathing interventions while driving to help manage stress. In particular, we implemented and evaluated a closed-loop system that monitored the breathing rate of drivers in real-time and delivered either a conscious or an unconscious personalized acoustic breathing guide whenever needed. In a study with 24 participants, we observed that conscious interventions more effectively reduced the breathing rate but also increased the number of driving mistakes. We observed that prior driving experience as well as personality are significantly associated with the effect of the interventions, which highlights the importance of considering user profiles for in-car stress management interventions.
 Monitoring changes in depression severity using wearable and mobile sensorsPaola Pedrelli , Szymon Fedor , Asma Ghandeharioun, Esther Howe , Dawn F Ionescu , Darian Bhathena , Lauren B Fisher , Cristina Cusin , Maren Nyer , Albert Yeung , and othersFrontiers in psychiatry, 2020
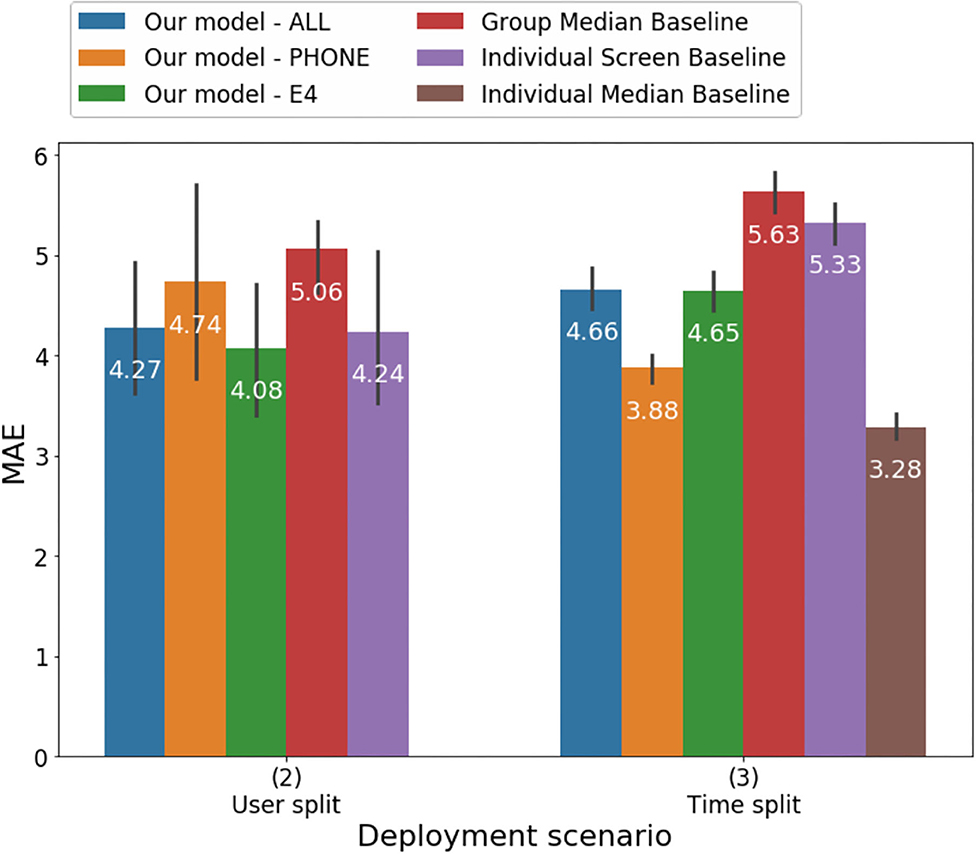
Monitoring changes in depression severity using wearable and mobile sensorsPaola Pedrelli , Szymon Fedor , Asma Ghandeharioun, Esther Howe , Dawn F Ionescu , Darian Bhathena , Lauren B Fisher , Cristina Cusin , Maren Nyer , Albert Yeung , and othersFrontiers in psychiatry, 2020Background: While preliminary evidence suggests that sensors may be employed to detect presence of low mood it is still unclear whether they can be leveraged for measuring depression symptom severity. This study evaluates the feasibility and performance of assessing depressive symptom severity by using behavioral and physiological features obtained from wristband and smartphone sensors. Method: Participants were thirty-one individuals with Major Depressive Disorder (MDD). The protocol included 8 weeks of behavioral and physiological monitoring through smartphone and wristband sensors and six in-person clinical interviews during which depression was assessed with the 17-item Hamilton Depression Rating Scale (HDRS-17). Results: Participants wore the right and left wrist sensors 92 and 94% of the time respectively. Three machine-learning models estimating depressive symptom severity were developed–one combining features from smartphone and wearable sensors, one including only features from the smartphones, and one including features from wrist sensors–and evaluated in two different scenarios. Correlations between the models’ estimate of HDRS scores and clinician-rated HDRS ranged from moderate to high (0.46 [CI: 0.42, 0.74] to 0.7 [CI: 0.66, 0.74]) and had moderate accuracy with Mean Absolute Error ranging between 3.88 ± 0.18 and 4.74 ± 1.24. The time-split scenario of the model including only features from the smartphones performed the best. The ten most predictive features in the model combining physiological and mobile features were related to mobile phone engagement, activity level, skin conductance, and heart rate variability. Conclusion: Monitoring of MDD patients through smartphones and wrist sensors following a clinician-rated HDRS assessment is feasible and may provide an estimate of changes in depressive symptom severity. Future studies should further examine the best features to estimate depressive symptoms and strategies to further enhance accuracy.




2019
 Approximating interactive human evaluation with self-play for open-domain dialog systemsAsma Ghandeharioun*, Judy Hanwen Shen* , Natasha Jaques* , Craig Ferguson , Noah Jones , Agata Lapedriza , and Rosalind W PicardIn Advances in Neural Information Processing Systems (NeurIPS) , 2019
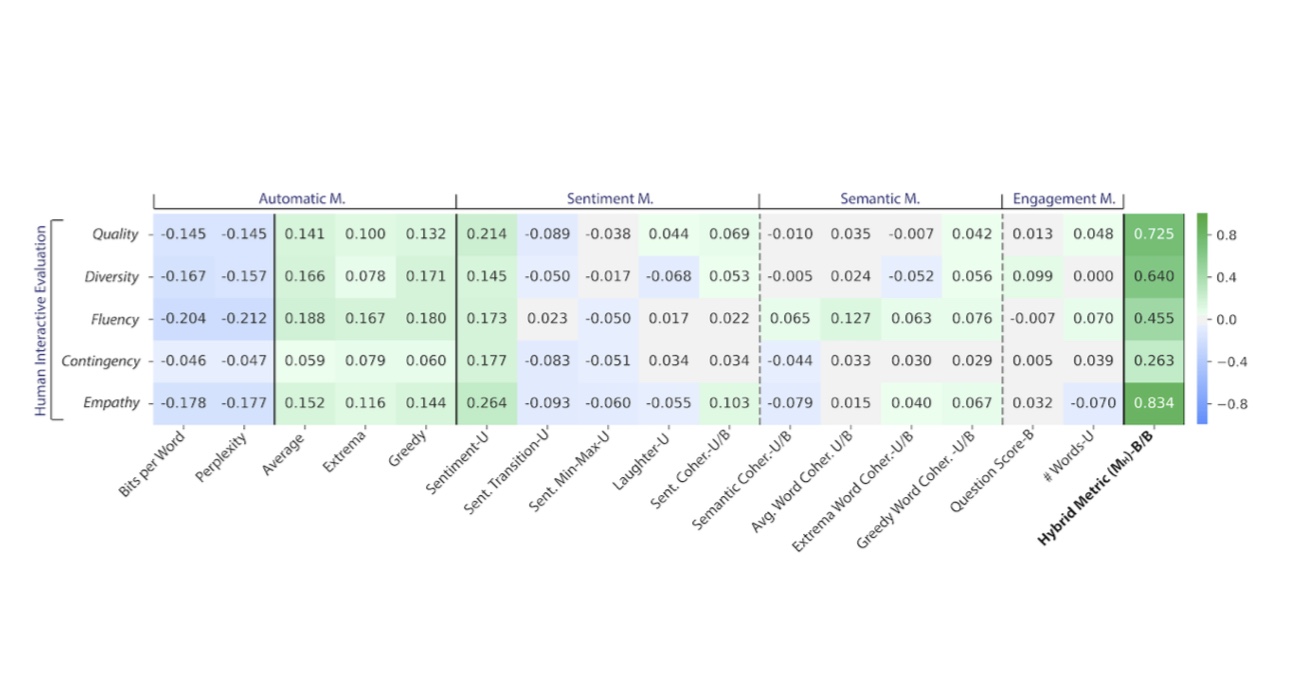
Approximating interactive human evaluation with self-play for open-domain dialog systemsAsma Ghandeharioun*, Judy Hanwen Shen* , Natasha Jaques* , Craig Ferguson , Noah Jones , Agata Lapedriza , and Rosalind W PicardIn Advances in Neural Information Processing Systems (NeurIPS) , 2019Building an open-domain conversational agent is a challenging problem. Current evaluation methods, mostly post-hoc judgments of static conversation, do not capture conversation quality in a realistic interactive context. In this paper, we investigate interactive human evaluation and provide evidence for its necessity; we then introduce a novel, model-agnostic, and dataset-agnostic method to approximate it. In particular, we propose a self-play scenario where the dialog system talks to itself and we calculate a combination of proxies such as sentiment and semantic coherence on the conversation trajectory. We show that this metric is capable of capturing the human-rated quality of a dialog model better than any automated metric known to-date, achieving a significant Pearson correlation (r>.7, p<.05). To investigate the strengths of this novel metric and interactive evaluation in comparison to state-of-the-art metrics and human evaluation of static conversations, we perform extended experiments with a set of models, including several that make novel improvements to recent hierarchical dialog generation architectures through sentiment and semantic knowledge distillation on the utterance level. Finally, we open-source the interactive evaluation platform we built and the dataset we collected to allow researchers to efficiently deploy and evaluate dialog models.
@inproceedings{ghandeharioun2019approximating, title = {Approximating interactive human evaluation with self-play for open-domain dialog systems}, author = {Ghandeharioun*, Asma and Shen*, Judy Hanwen and Jaques*, Natasha and Ferguson, Craig and Jones, Noah and Lapedriza, Agata and Picard, Rosalind W}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, volume = {32}, year = {2019}, }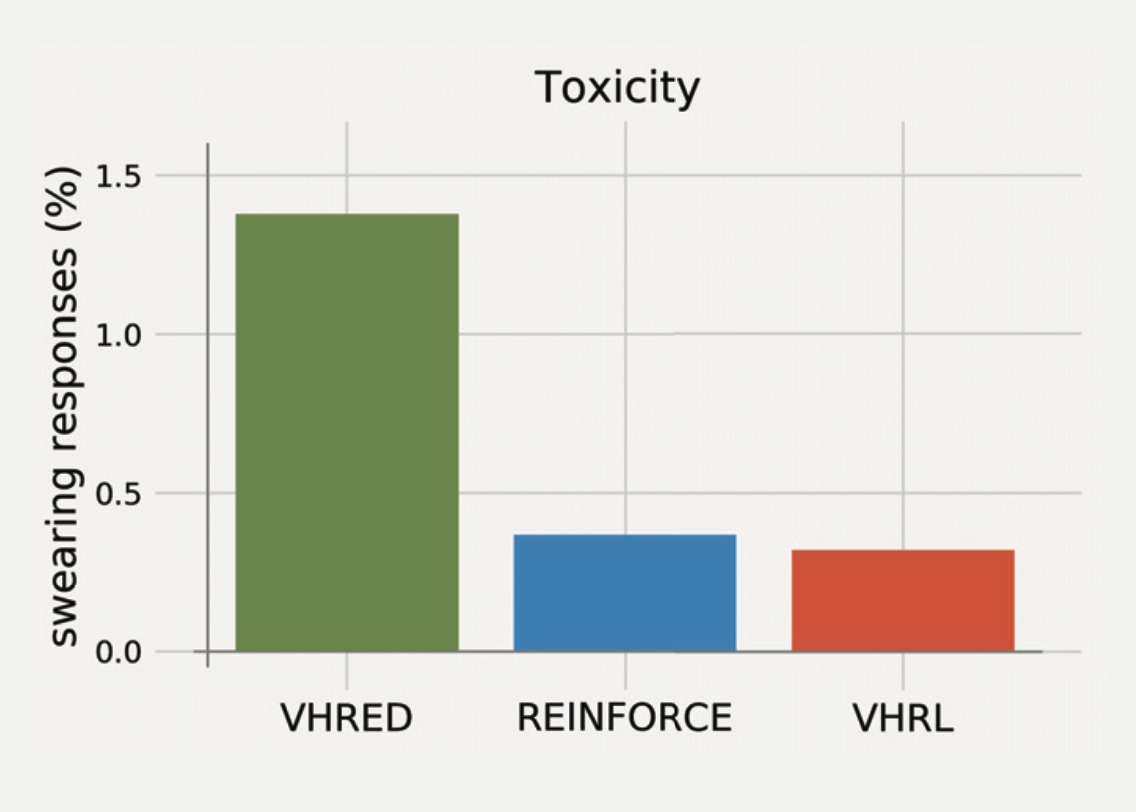 Hierarchical reinforcement learning for open-domain dialogAbdelrhman Saleh* , Natasha Jaques* , Asma Ghandeharioun, Judy Shen , and Rosalind W PicardIn Conversational AI (NeurIPS-W) , 2019(Best paper nominee)
Hierarchical reinforcement learning for open-domain dialogAbdelrhman Saleh* , Natasha Jaques* , Asma Ghandeharioun, Judy Shen , and Rosalind W PicardIn Conversational AI (NeurIPS-W) , 2019(Best paper nominee)Open-domain dialog generation is a challenging problem; maximum likelihood training can lead to repetitive outputs, models have difficulty tracking long-term conversational goals, and training on standard movie or online datasets may lead to the generation of inappropriate, biased, or offensive text. Reinforcement Learning (RL) is a powerful framework that could potentially address these issues, for example by allowing a dialog model to optimize for reducing toxicity and repetitiveness. However, previous approaches which apply RL to open-domain dialog generation do so at the word level, making it difficult for the model to learn proper credit assignment for long-term conversational rewards. In this paper, we propose a novel approach to hierarchical reinforcement learning, VHRL, which uses policy gradients to tune the utterance-level embedding of a variational sequence model. This hierarchical approach provides greater flexibility for learning long-term, conversational rewards. We use self-play and RL to optimize for a set of human-centered conversation metrics, and show that our approach provides significant improvements – in terms of both human evaluation and automatic metrics – over state-of-the-art dialog models, including Transformers.
@inproceedings{saleh2020hierarchicam, title = {Hierarchical reinforcement learning for open-domain dialog}, author = {Saleh*, Abdelrhman and Jaques*, Natasha and Ghandeharioun, Asma and Shen, Judy and Picard, Rosalind W}, booktitle = {Conversational AI (NeurIPS-W)}, year = {2019}, } Way off-policy batch deep reinforcement learning of implicit human preferences in dialogNatasha Jaques , Asma Ghandeharioun, Judy Hanwen Shen , Craig Ferguson , Agata Lapedriza , Noah Jones , Shixiang Gu , and Rosalind W PicardConversational AI (NeurIPS-W), 2019
Way off-policy batch deep reinforcement learning of implicit human preferences in dialogNatasha Jaques , Asma Ghandeharioun, Judy Hanwen Shen , Craig Ferguson , Agata Lapedriza , Noah Jones , Shixiang Gu , and Rosalind W PicardConversational AI (NeurIPS-W), 2019Most deep reinforcement learning (RL) systems are not able to learn effectively from off-policy data, especially if they cannot explore online in the environment. These are critical shortcomings for applying RL to real-world problems where collecting data is expensive, and models must be tested offline before being deployed to interact with the environment – e.g. systems that learn from human interaction. Thus, we develop a novel class of off-policy batch RL algorithms, which are able to effectively learn offline, without exploring, from a fixed batch of human interaction data. We leverage models pre-trained on data as a strong prior, and use KL-control to penalize divergence from this prior during RL training. We also use dropout-based uncertainty estimates to lower bound the target Q-values as a more efficient alternative to Double Q-Learning. The algorithms are tested on the problem of open-domain dialog generation – a challenging reinforcement learning problem with a 20,000-dimensional action space. Using our Way Off-Policy algorithm, we can extract multiple different reward functions post-hoc from collected human interaction data, and learn effectively from all of these. We test the real-world generalization of these systems by deploying them live to converse with humans in an open-domain setting, and demonstrate that our algorithm achieves significant improvements over prior methods in off-policy batch RL.
@article{jaques2019way, title = {Way off-policy batch deep reinforcement learning of implicit human preferences in dialog}, author = {Jaques, Natasha and Ghandeharioun, Asma and Shen, Judy Hanwen and Ferguson, Craig and Lapedriza, Agata and Jones, Noah and Gu, Shixiang and Picard, Rosalind W}, journal = {Conversational AI (NeurIPS-W)}, year = {2019}, }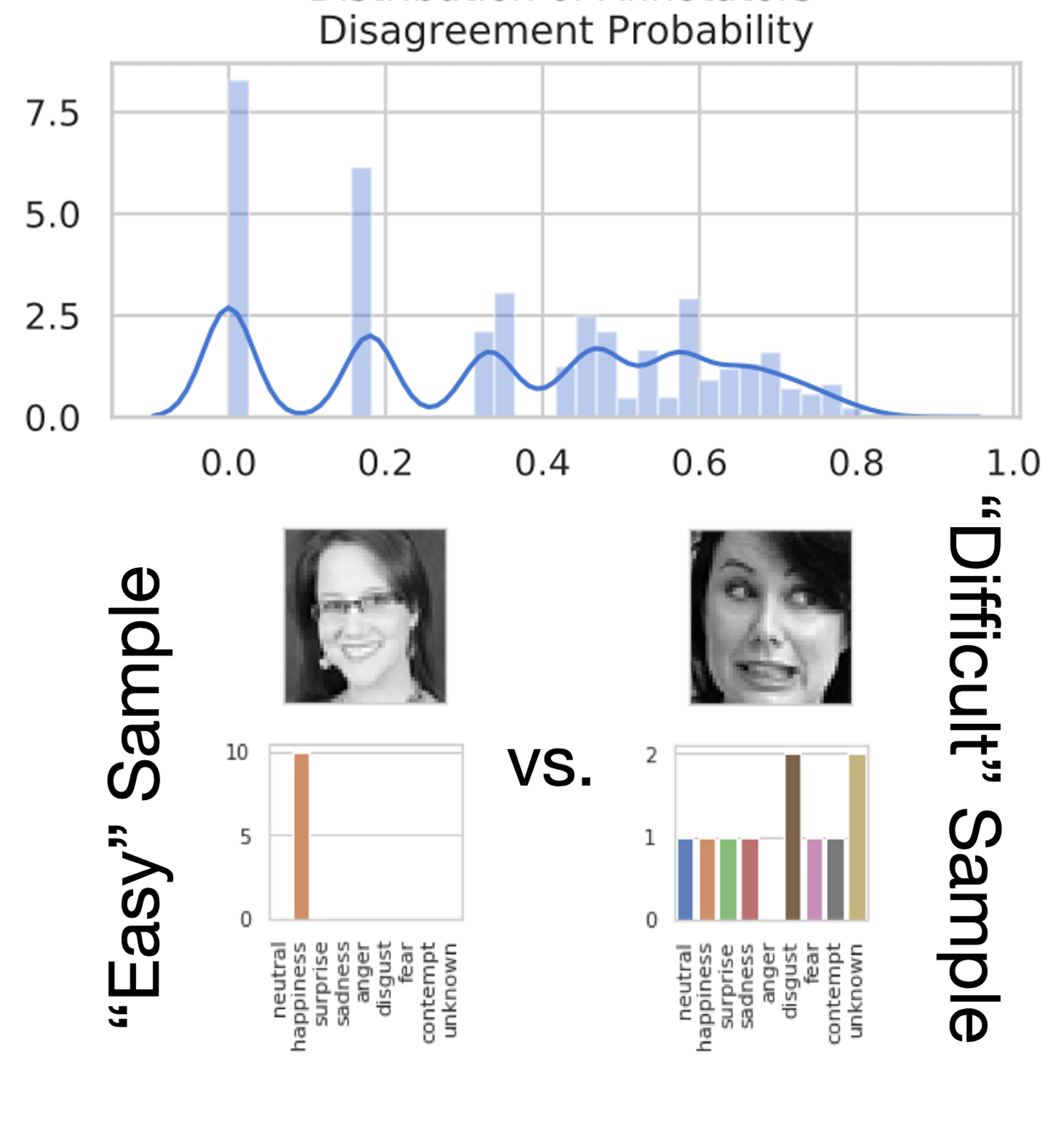 Characterizing sources of uncertainty to proxy calibration and disambiguate annotator and data biasAsma Ghandeharioun, Brian Eoff , Brendan Jou , and Rosalind PicardIn 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCV-W) , 2019(Oral)
Characterizing sources of uncertainty to proxy calibration and disambiguate annotator and data biasAsma Ghandeharioun, Brian Eoff , Brendan Jou , and Rosalind PicardIn 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCV-W) , 2019(Oral)Supporting model interpretability for complex phenomena where annotators can legitimately disagree, such as emotion recognition, is a challenging machine learning task. In this work, we show that explicitly quantifying the uncertainty in such settings has interpretability benefits. We use a simple modification of a classical network inference using Monte Carlo dropout to give measures of epistemic and aleatoric uncertainty. We identify a significant correlation between aleatoric uncertainty and human annotator disagreement (r≈.3). Additionally, we demonstrate how difficult and subjective training samples can be identified using aleatoric uncertainty and how epistemic uncertainty can reveal data bias that could result in unfair predictions. We identify the total uncertainty as a suitable surrogate for model calibration, i.e. the degree we can trust model’s predicted confidence. In addition to explainability benefits, we observe modest performance boosts from incorporating model uncertainty.
@inproceedings{ghandeharioun2019characterizing, title = {Characterizing sources of uncertainty to proxy calibration and disambiguate annotator and data bias}, author = {Ghandeharioun, Asma and Eoff, Brian and Jou, Brendan and Picard, Rosalind}, booktitle = {2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCV-W)}, pages = {4202--4206}, year = {2019}, organization = {IEEE}, } EMMA: An Emotion-Aware Wellbeing ChatbotAsma Ghandeharioun, Daniel McDuff , Mary Czerwinski , and Kael RowanIn 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII) , 2019
EMMA: An Emotion-Aware Wellbeing ChatbotAsma Ghandeharioun, Daniel McDuff , Mary Czerwinski , and Kael RowanIn 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII) , 2019The delivery of mental health interventions via ubiquitous devices has shown much promise. A conversational chatbot is a promising oracle for delivering appropriate just-in-time interventions. However, designing emotionally-aware agents, specially in this context, is under-explored. Furthermore, the feasibility of automating the delivery of just-in-time mHealth interventions via such an agent has not been fully studied. In this paper, we present the design and evaluation of EMMA (EMotion-Aware mHealth Agent) through a two-week long human-subject experiment with N=39 participants. EMMA provides emotionally appropriate micro-activities in an empathetic manner. We show that the system can be extended to detect a user’s mood purely from smartphone sensor data. Our results show that our personalized machine learning model was perceived as likable via self-reports of emotion from users. Finally, we provide a set of guidelines for the design of emotion-aware bots for mHealth.
@inproceedings{ghandeharioun2019emma, title = {EMMA: An Emotion-Aware Wellbeing Chatbot}, author = {Ghandeharioun, Asma and McDuff, Daniel and Czerwinski, Mary and Rowan, Kael}, booktitle = {2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII)}, year = {2019}, organization = {IEEE}, } Towards understanding emotional intelligence for behavior change chatbotsAsma Ghandeharioun, Daniel McDuff , Mary Czerwinski , and Kael RowanIn 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII) , 2019
Towards understanding emotional intelligence for behavior change chatbotsAsma Ghandeharioun, Daniel McDuff , Mary Czerwinski , and Kael RowanIn 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII) , 2019A natural conversational interface that allows longitudinal symptom tracking would be extremely valuable in health/wellness applications. However, the task of designing emotionally-aware agents for behavior change is still poorly understood. In this paper, we present the design and evaluation of an emotion-aware chatbot that conducts experience sampling in an empathetic manner. We evaluate it through a human-subject experiment with N=39 participants over the course of a week. Our results show that extraverts preferred the emotion-aware chatbot significantly more than introverts. Also, participants reported a higher percentage of positive mood reports when interacting with the empathetic bot. Finally, we provide guidelines for the design of emotion-aware chatbots for potential use in mHealth contexts.
@inproceedings{ghandeharioun2019towards, title = {Towards understanding emotional intelligence for behavior change chatbots}, author = {Ghandeharioun, Asma and McDuff, Daniel and Czerwinski, Mary and Rowan, Kael}, booktitle = {2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII)}, pages = {8--14}, year = {2019}, organization = {IEEE}, } Engineering music to slow breathing and invite relaxed physiologyGrace Leslie , Asma Ghandeharioun, Diane Zhou , and Rosalind W PicardIn 2019 8th international conference on Affective Computing and Intelligent Interaction (ACII) , 2019
Engineering music to slow breathing and invite relaxed physiologyGrace Leslie , Asma Ghandeharioun, Diane Zhou , and Rosalind W PicardIn 2019 8th international conference on Affective Computing and Intelligent Interaction (ACII) , 2019We engineered an interactive music system that influences a user’s breathing rate to induce a relaxation response. This system generates ambient music containing periodic shifts in loudness that are determined by the user’s own breathing patterns. We evaluated the efficacy of this music intervention for participants who were engaged in an attention-demanding task, and thus explicitly not focusing on their breathing or on listening to the music. We measured breathing patterns in addition to multiple peripheral and cortical indicators of physiological arousal while users experienced three different interaction designs: (1) a “Fixed Tempo” amplitude modulation rate at six beats per minute; (2) a “Personalized Tempo” modulation rate fixed at 75% of each individual’s breathing rate baseline, and (3) a “Personalized Envelope” design in which the amplitude modulation matches each individual’s breathing pattern in real-time. Our results revealed that each interactive music design slowed down breathing rates, with the “Personalized Tempo” design having the largest effect, one that was more significant than the non-personalized design. The physiological arousal indicators (electrodermal activity, heart rate, and slow cortical potentials measured in EEG) showed concomitant reductions, suggesting that slowing users’ breathing rates shifted them towards a more calmed state. These results suggest that interactive music incorporating biometric data may have greater effects on physiology than traditional recorded music.
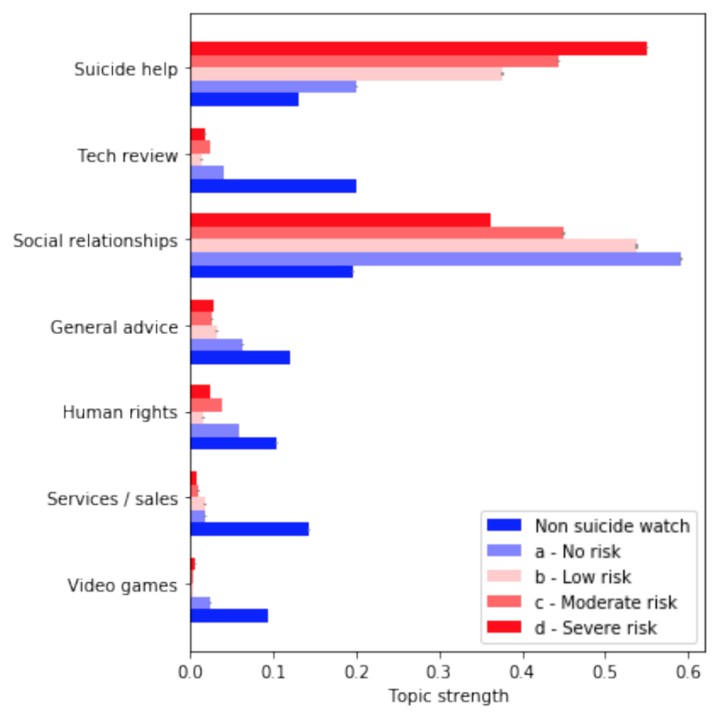 Analysis of online suicide risk with document embeddings and latent dirichlet allocationNoah Jones , Natasha Jaques , Pat Pataranutaporn , Asma Ghandeharioun, and Rosalind W PicardIn 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW) , 2019
Analysis of online suicide risk with document embeddings and latent dirichlet allocationNoah Jones , Natasha Jaques , Pat Pataranutaporn , Asma Ghandeharioun, and Rosalind W PicardIn 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW) , 2019Machine learning to infer suicide risk and urgency is applied to a dataset of Reddit users in which the risk and urgency labels were derived from crowdsource consensus. We present the results of machine learning models based on transfer learning from document embeddings trained on large external corpora, and find that they have very high F1 scores (.83 -. 92) in distinguishing which users are labeled as being most at risk of committing suicide. We further show that the document embedding approach outperforms a method based on word importance, where important words were identified by domain experts. Finally, we find, using a Latent Dirichlet Allocation (LDA) topic model, that users labeled at-risk for suicide post about different topics to the rest of Reddit than non-suicidal users.








2018
 Depression and emotional reactivity: a closer examination of daily variations in affectEsther Howe , Maya Nauphal , Ben Shapero , Kate Bentley , David Mischoulon , Asma Ghandeharioun, Szymon Fedor , Rosalind W Picard , and Paola PedrelliAssociation for Behavioral and Cognitive Therapies Annual Convention (ABCT), 2018
Depression and emotional reactivity: a closer examination of daily variations in affectEsther Howe , Maya Nauphal , Ben Shapero , Kate Bentley , David Mischoulon , Asma Ghandeharioun, Szymon Fedor , Rosalind W Picard , and Paola PedrelliAssociation for Behavioral and Cognitive Therapies Annual Convention (ABCT), 2018

2017
 BrightBeat: Effortlessly influencing breathing for cultivating calmness and focusAsma Ghandeharioun, and Rosalind W PicardIn Proceedings of the 2017 CHI conference extended abstracts on human factors in computing systems , 2017
BrightBeat: Effortlessly influencing breathing for cultivating calmness and focusAsma Ghandeharioun, and Rosalind W PicardIn Proceedings of the 2017 CHI conference extended abstracts on human factors in computing systems , 2017While technology is usually associated with causing stress, technology also has the potential to bring about calm. In particular, breathing usually speeds up with higher stress, but it can be slowed through a manipulation, and in so doing, it can help the person lower their stress and improve their focus. This paper introduces BrightBeat, a set of seamless visual and auditory interventions that look like respiratory biofeedback, rhythmically oscillating, but that are tuned to appear with a slower speed, with the aim of slowing a stressed computer user’s breathing and, consequently, bringing a sense of focus and calmness. These interventions were designed to run easily on commonplace personal electronic devices and to not require any focused attention in order to be effective. We have run a randomized placebo-controlled trial and examined both objective and subjective measures of impact with N=32 users undergoing work tasks. BrightBeat significantly influenced slower breathing, had a lasting effect, improved self-reported calmness and focus, and was highly preferred for future use.
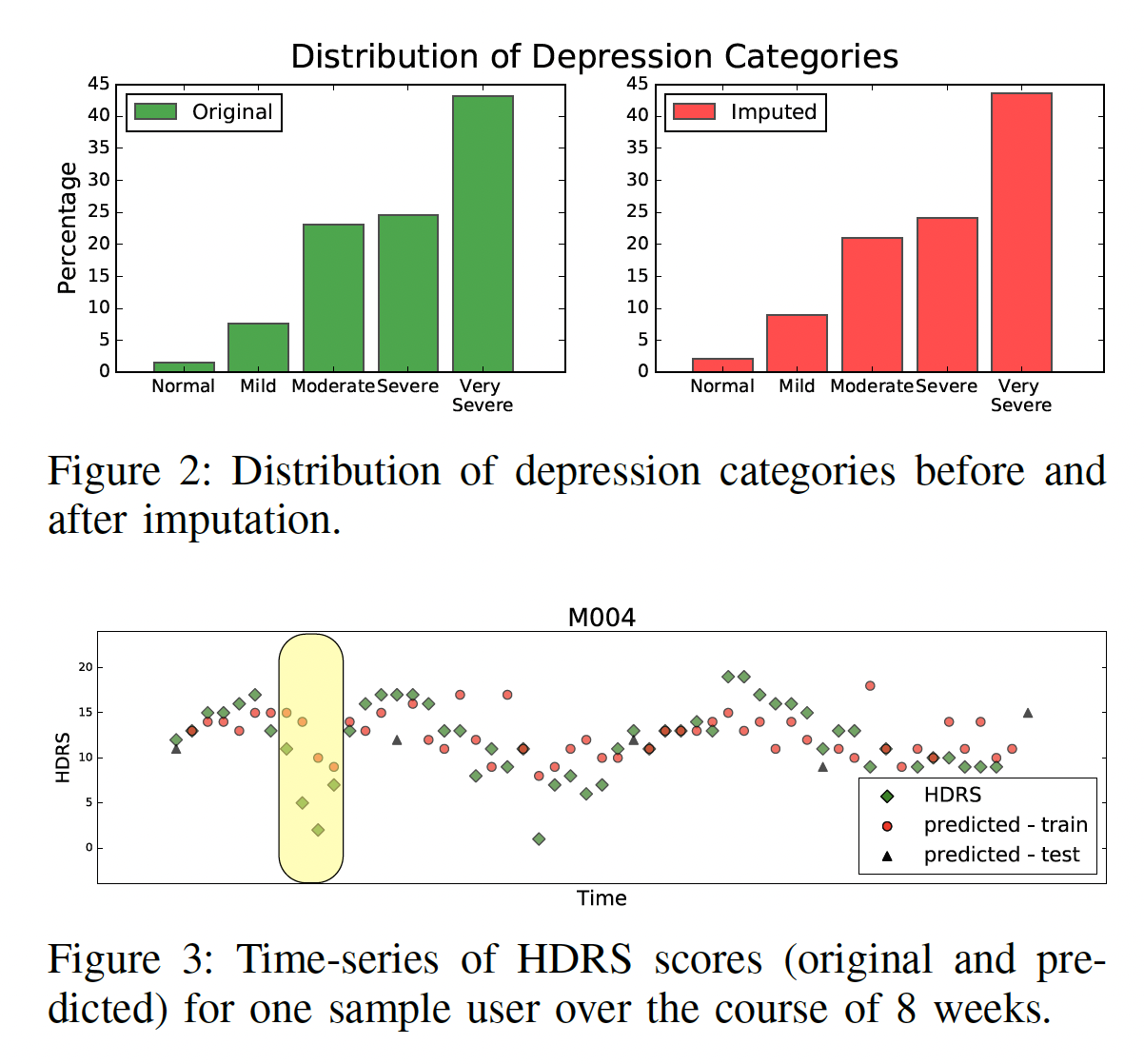 Objective Assessment of Depressive Symptoms with Machine Learning and Wearable Sensors DataAsma Ghandeharioun, Szymon Fedor , Lisa Sangermano , Dawn F Ionescu , Jonathan Alpert , Chelsea Dale , David Sontag , and Rosalind W PicardIn 2017 7th international conference on Affective Computing and Intelligent Interaction (ACII) , 2017
Objective Assessment of Depressive Symptoms with Machine Learning and Wearable Sensors DataAsma Ghandeharioun, Szymon Fedor , Lisa Sangermano , Dawn F Ionescu , Jonathan Alpert , Chelsea Dale , David Sontag , and Rosalind W PicardIn 2017 7th international conference on Affective Computing and Intelligent Interaction (ACII) , 2017Depression is the major cause of years lived in disability world-wide; however, its diagnosis and tracking methods still rely mainly on assessing self-reported depressive symptoms, methods that originated more than fifty years ago. These methods, which usually involve filling out surveys or engaging in face-to-face interviews, provide limited accuracy and reliability and are costly to track and scale. In this paper, we develop and test the efficacy of machine learning techniques applied to objective data captured passively and continuously from E4 wearable wristbands and from sensors in an Android phone for predicting the Hamilton Depression Rating Scale (HDRS). Input data include electrodermal activity (EDA), sleep behavior, motion, phone-based communication, location changes, and phone usage patterns. We introduce our feature generation and transformation process, imputing missing clinical scores from self-reported measures, and predicting depression severity from continuous sensor measurements. While HDRS ranges between 0 and 52, we were able to impute it with 2.8 RMSE and predict it with 4.5 RMSE which are low relative errors. Analyzing the features and their relation to depressive symptoms, we found that poor mental health was accompanied by more irregular sleep, less motion, fewer incoming messages, less variability in location patterns, and higher asymmetry of EDA between the right and the left wrists.
 Integrating EMA, Clinical Assessment and Wearable Sensors to Examine the Association between Major Depressive Disorder (MDD) and Alcohol UsePaola Pedrelli , Esther Howe , David Mischoulon , Rosalind W Picard , Asma Ghandeharioun, and Szymon FedorConnected Health Conference, 2017
Integrating EMA, Clinical Assessment and Wearable Sensors to Examine the Association between Major Depressive Disorder (MDD) and Alcohol UsePaola Pedrelli , Esther Howe , David Mischoulon , Rosalind W Picard , Asma Ghandeharioun, and Szymon FedorConnected Health Conference, 2017Background: Depression is the leading cause of disability worldwide. Heavy drinking often co-occurs with Major Depressive Disorder (MDD), preventing the amelioration of symptoms and increasing disability. New technology-based assessment tools such as ecological momentary assessment (EMA) and wearable sensors provide the opportunity for a more detailed examination of the interplay between these two conditions. While the association between low mood and heavy drinking has been extensively examined, multi-method assessments including EMA, sensors and clinician-rated measures have not been utilized to study the association between depression and heavy alcohol use. Objective: To examine the association between depressive symptoms and alcohol consumption by integrating multiple sources of data including EMA, clinical assessment, and wearable sensors. Methods: Individuals with MDD complete an 8-week protocol that involves tracking depressive symptoms and alcohol consumption daily through an EMA. Mood is captured via surveys delivered twice daily that include 10 items of the Positive and Negative Affect Scale (PANAS) assessing negative affect (NA) and positive affect (PA). Participants wear Empatica E4 wristband sensors that track electrodermal activity (EDA) and accelerometer data 23 hours/day. The clinician-rated Hamilton Depression Rating Scale (HDRS) is administered biweekly to assess depressive symptoms. MovisensXS, the app delivering the EMA, tracks text messages, phone calls, location, app usage, and screen on/off behavior. Results: To date, 16 of 30 projected participants have completed the study. All participants are expected to complete the study by 10/2017. Preliminary analyses confirmed the accuracy of the daily mood ratings. There was a significant linear relationship between NA/PA ratio from EMA ratings and the clinician-based ratings (P=1.3e-6). To focus on the association of low mood and drinking behavior, we solely included instances where NA>=PA and observed a significant association (P=0.001) between low mood (as a ratio of total NA divided by PA) and higher alcohol use. Analyses will be repeated for all 30 participants. E4 accelerometer data and location data will help elucidate whether mobility moderates the association between mood and depression, such that individuals who drink at home may exhibit greater depressive symptomatology. Finally, the association between EDA and alcohol use will be examined. Final results will be presented at the Connected Health Conference. Conclusions: To date, results show a significant association between low mood and alcohol consumption. Results of planned analyses will further clarify the temporal association between mood and alcohol use among depressed patients, and possible moderators and mediators of this relationship. A precise understanding of the association between low mood, physiological states and heavy drinking will facilitate the development of “just-in-time” ecological momentary interventions for both reduction of depressed mood and heavy drinking.
 Objective vs. Subjective Reports of Sleep Quality in Major Depressive Disorder: A Pilot StudyAsma Ghandeharioun, Lisa Sangermano , Rosalind W Picard , Jonathan Alpert , Chelsea Dale , Dawn F Ionescu , and Szymon FedorAnxiety and Depression Association of America (ADAA), 2017
Objective vs. Subjective Reports of Sleep Quality in Major Depressive Disorder: A Pilot StudyAsma Ghandeharioun, Lisa Sangermano , Rosalind W Picard , Jonathan Alpert , Chelsea Dale , Dawn F Ionescu , and Szymon FedorAnxiety and Depression Association of America (ADAA), 2017Background: The diagnosis of major depressive disorder (MDD) is heterogeneous. For example, depressed patients exhibit varied patterns of sleep; both insomnia and hypersomnia are symptoms of depression. Assessment of sleep patterns in MDD is often limited by clinicians’ reliance on subjective self-ratings of sleep quality. Objective measures, such as sleep regularity measured by accelerometer data, may provide a more accurate understanding. This study assessed the extent to which objective sleep quality measures could detect differences among individuals with MDD. We hypothesized that we would observe variability in sleep regularity and patterns among depressed individuals. We also hypothesized that there would be a strong correlation between subjective sleep ratings and objective measurements. Methods: Between April and October 2016, patients with MDD (n=4) and healthy volunteers (n=2) completed a protocol that involved tracking depressive symptoms and wearing Empatica E4 wristbands that recorded accelerometer data. Patients wore sensors 23 hours daily and were clinically assessed for depression symptoms and stress levels biweekly for 8 weeks using the Hamilton Depression Rating Scale (HDRS). We developed an algorithm to calculate objective sleep based on accelerometer data. We calculated sleep regularity indices for both objective and subjective sleep. We utilized Pearson correlation to compare sleep regularity indices and t-statistics to compare the sleep regularity between depressed and healthy samples. Results: On average, the objective (accelerometer-based) and subjective (self-reported) sleep/awake time periods matched 74.52% of the time for each user (std=6.55%). A trend toward positive correlation between objective and subjective sleep regularity indices did not reach statistical significance in this small sample (r=0.79, p=0.06). Another trend that suggested depressed users had a lower objective sleep regularity index was also not significant (p=0.14). Conclusion: Our analyses revealed that individuals’ subjective sleep ratings and objective data from the E4 sensors were potentially correlated but did not reach significance in this sample. Further analyses also suggested an association between lower objective sleep regularity and depressive symptoms as measured by the HDRS. We are continuing to recruit new patients for this protocol and further data will be reported from the larger sample during the conference.
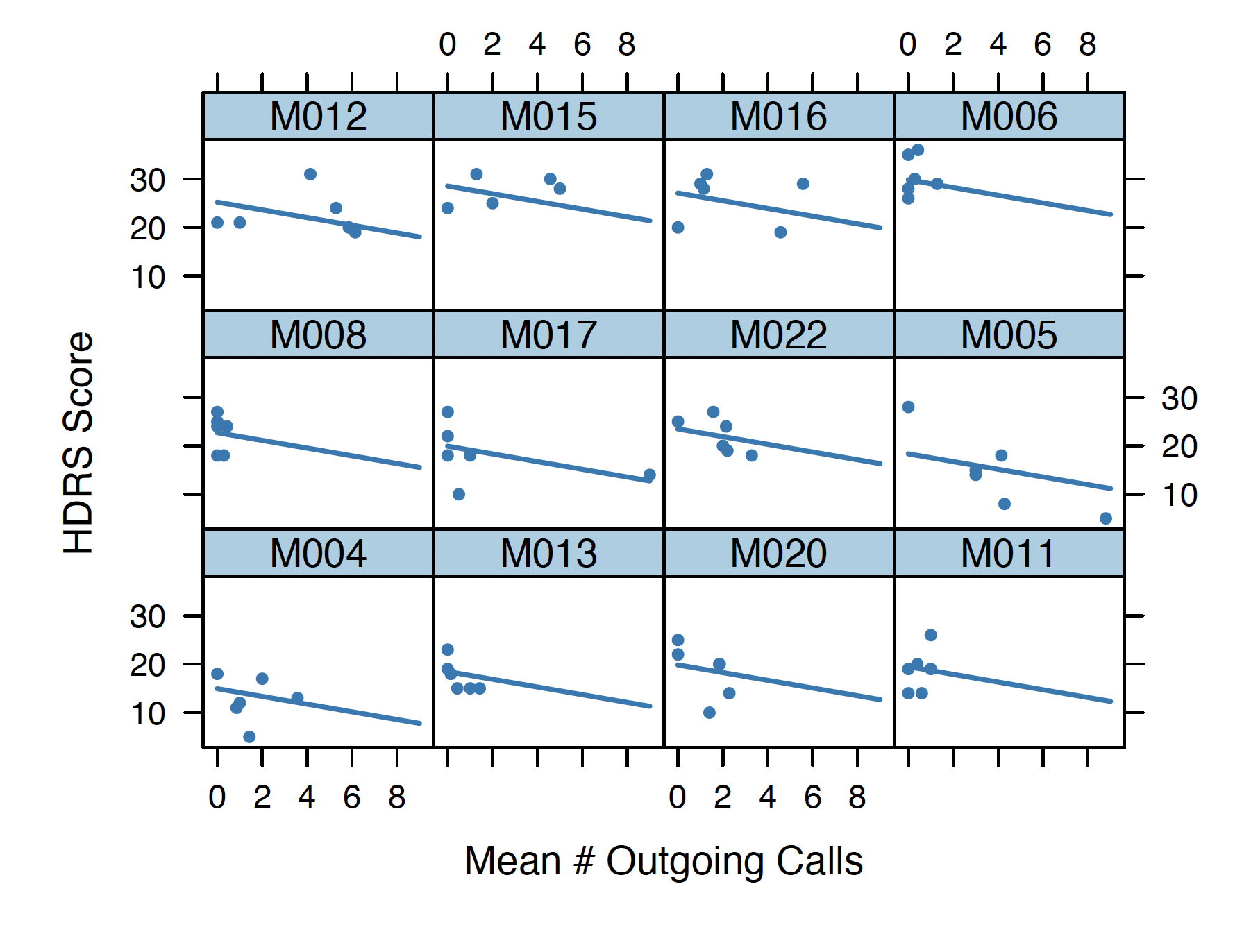 Cell phone data as a potential predictor of depression severity: a pilot studyLisa Sangermano , Asma Ghandeharioun, Rosalind W Picard , Jonathan Alpert , Chelsea Dale , Szymon Fedor , and Dawn F IonescuAnxiety and Depression Association of America (ADAA), 2017
Cell phone data as a potential predictor of depression severity: a pilot studyLisa Sangermano , Asma Ghandeharioun, Rosalind W Picard , Jonathan Alpert , Chelsea Dale , Szymon Fedor , and Dawn F IonescuAnxiety and Depression Association of America (ADAA), 2017Background: Major depressive disorder (MDD) is a serious and prevalent disease with an unpredictable course. Cell phone technology can assist doctors by monitoring patients’ symptoms, and may eventually be useful in the prediction of depressive episode time courses. However, the extent to which the course of depression can be predicted with cell phone data remains unknown. The quantitative measurement of communication patterns (i.e., number of text messages and phone calls) between depressed patients and their contacts may be useful for the prognostication of the course of depression. We predicted that more communication with social contacts via texts and phone calls would correlate with lower depression scores. Methods: Between April 2016 and March 2017, patients with MDD (n=12) and healthy volunteers (n=4) completed an 8-week protocol that involved tracking depressive symptoms and mobile phone usage. All patients were assessed at 2-week intervals for depression symptoms as measured with the Hamilton Depression Rating Scale (HDRS). Movisens (an Android application) was used to measure incoming and outgoing SMS (text messages) and phone calls, and missed calls. We used linear mixed-effects models with random intercepts and slopes to assess the relationship between the HDRS total score and the number of calls/texts in the week prior to clinical assessment. Results: An increased duration of calls received during the week prior to clinical assessment were related to increases in total HDRS scores (t=0.005, p=0.012). However, an increased number of calls made during the week prior to the assessment were related to decreases in total HDRS scores (t=-0.887, p=0.033). Conclusion: Contrary to our hypothesis, depressed patients with longer incoming calls in the week prior to their study visit had significantly more subjectively reported symptoms of depression. Though the content of interactions was unknown, this may represent a relationship between negative interactions with social contacts and increased depressive symptoms. Alternatively, as patients’ social contacts begin to suspect worsening depression, they may mobilize support through cell phone communications. Further research is necessary to discern the context of social connectedness and symptoms of depression. On the other hand, the HDRS symptoms improved as the depressed individual made more calls the week prior to the assessment. This could be interpreted as the social interactions that are made at will can improve the depressive symptoms.
 Location patterns from phone sensors may help predict depressive symptoms: a longitudinal pilot studyEsther Howe , Asma Ghandeharioun, Paola Pedrelli , David Mischoulon , Rosalind W Picard , and Szymon FedorAssociation for Behavioral and Cognitive Therapies Annual Convention –Tech SIG (ABCT), 2017
Location patterns from phone sensors may help predict depressive symptoms: a longitudinal pilot studyEsther Howe , Asma Ghandeharioun, Paola Pedrelli , David Mischoulon , Rosalind W Picard , and Szymon FedorAssociation for Behavioral and Cognitive Therapies Annual Convention –Tech SIG (ABCT), 2017Major depressive disorder (MDD) is a serious and prevalent disease with a variable course. Ubiquitous smartphone technology has the potential to inform and improve clinical care by monitoring patients’ symptoms and behavioral patterns.The extent to which the changes in depressive symptoms can be predicted with cell phone data remains unknown.
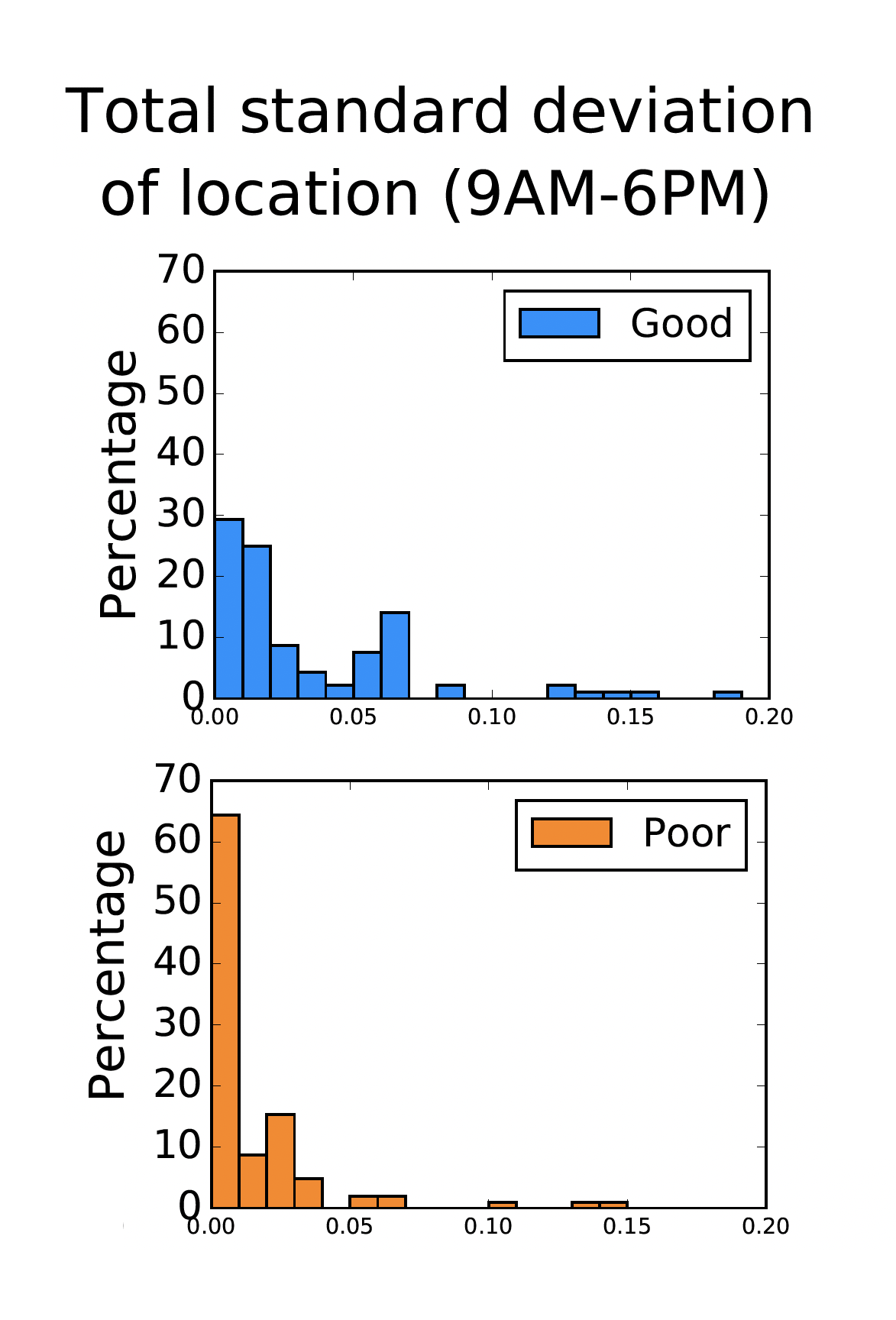
 Location variability from commodity phone sensors is negatively associated with self-reported depression score: a pilot studyAsma Ghandeharioun, Szymon Fedor , Lisa Sangermano , Jonathan Alpert , Chelsea Dale , Dawn F Ionescu , and Rosalind W PicardAssociation for Psychological Science (APS), 2017
Location variability from commodity phone sensors is negatively associated with self-reported depression score: a pilot studyAsma Ghandeharioun, Szymon Fedor , Lisa Sangermano , Jonathan Alpert , Chelsea Dale , Dawn F Ionescu , and Rosalind W PicardAssociation for Psychological Science (APS), 2017







2016
 "Kind and Grateful": A context-sensitive smartphone app utilizing inspirational content to promote gratitudeAsma Ghandeharioun, Asaph Azaria , Sara Taylor , and Rosalind W PicardPsychology of well-being, 2016
"Kind and Grateful": A context-sensitive smartphone app utilizing inspirational content to promote gratitudeAsma Ghandeharioun, Asaph Azaria , Sara Taylor , and Rosalind W PicardPsychology of well-being, 2016Background: Previous research has shown that gratitude positively influences psychological wellbeing and physical health. Grateful people are reported to feel more optimistic and happy, to better mitigate aversive experiences, and to have stronger interpersonal bonds. Gratitude interventions have been shown to result in improved sleep, more frequent exercise and stronger cardiovascular and immune systems. These findings call for the development of technologies that would inspire gratitude. This paper presents a novel system designed toward this end. Methods: We leverage pervasive technologies to naturally embed inspiration to express gratitude in everyday life. Novel to this work, mobile sensor data is utilized to infer optimal moments for stimulating contextually relevant thankfulness and appreciation. Sporadic mood measurements are inventively obtained through the smartphone lock screen, investigating their interplay with grateful expressions. Both momentary thankful emotion and dispositional gratitude are measured. To evaluate our system, we ran two rounds of randomized control trials (RCT), including a pilot study (N = 15, 2 weeks) and a main study (N = 27, 5 weeks). Studies’ participants were provided with a newly developed smartphone app through which they were asked to express gratitude; the app displayed inspirational content to only the intervention group, while measuring contextual cues for all users. Results: In both rounds of the RCT, the intervention was associated with improved thankful behavior. Significant increase was observed in multiple facets of practicing gratitude in the intervention groups. The average frequency of practicing thankfulness increased by more than 120 %, comparing the baseline weeks with the intervention weeks of the main study. In contrast, the control group of the same study exhibited a decrease of 90 % in the frequency of thankful expressions. In the course of the study’s 5 weeks, increases in dispositional gratitude and in psychological wellbeing were also apparent. Analyzing the relation between mood and gratitude expressions, our data suggest that practicing gratitude increases the probability of going up in terms of emotional valence and down in terms of emotional arousal. The influences of inspirational content and contextual cues on promoting thankful behavior were also analyzed: We present data suggesting that the more successful times for eliciting expressions of gratitude tend to be shortly after a social experience, shortly after location change, and shortly after physical activity. Conclusions: The results support our intervention as an impactful method to promote grateful affect and behavior. Moreover, they provide insights into design and evaluation of general behavioral intervention technologies.
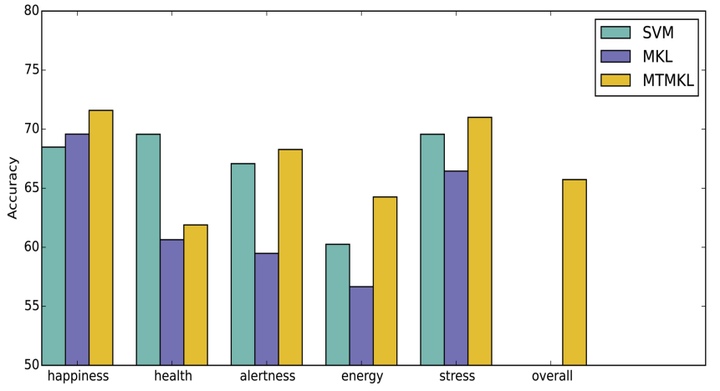 Machine learning of sleep and wake behaviors to classify self-reported evening moodSara Taylor , Natasha Jaques , Akane Sano , Asaph Azaria , Asma Ghandeharioun, and Rosalind W PicardSLEEP, 2016
Machine learning of sleep and wake behaviors to classify self-reported evening moodSara Taylor , Natasha Jaques , Akane Sano , Asaph Azaria , Asma Ghandeharioun, and Rosalind W PicardSLEEP, 2016The SNAPSHOT Study is a large-scale and long-term study that seeks to measure: Sleep, Networks, Affect, Performance, Stress, and Health using Objective Techniques. This study investigates: (1) how daily behaviors influence sleep, stress, mood, and other wellbeing-related factors (2) how accurately we can recognize/predict stress, mood and wellbeing (3) how interactions in a social network influence sleep behaviors. In this work we investigate the use of machine learning methods, using sleep and wake data, to predict mood. We seek to model behavioral patterns to predict these downturns in mood and begin to understand what will help build resilience to depression. Our results reveal that stress and happiness can be predicted most reliably from these signals, and that data collected while participants were asleep is particularly important to classifying happiness.
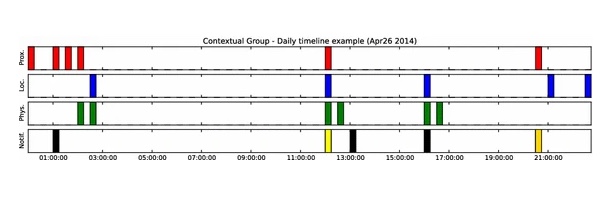 Promoting kindness and gratitude with a smartphone and triggersAsma Ghandeharioun, Asaph Azaria , Sara Taylor , Pattie Maes , and Rosalind W PicardAnnals of Behavioral Medicine, 2016
Promoting kindness and gratitude with a smartphone and triggersAsma Ghandeharioun, Asaph Azaria , Sara Taylor , Pattie Maes , and Rosalind W PicardAnnals of Behavioral Medicine, 2016



2015
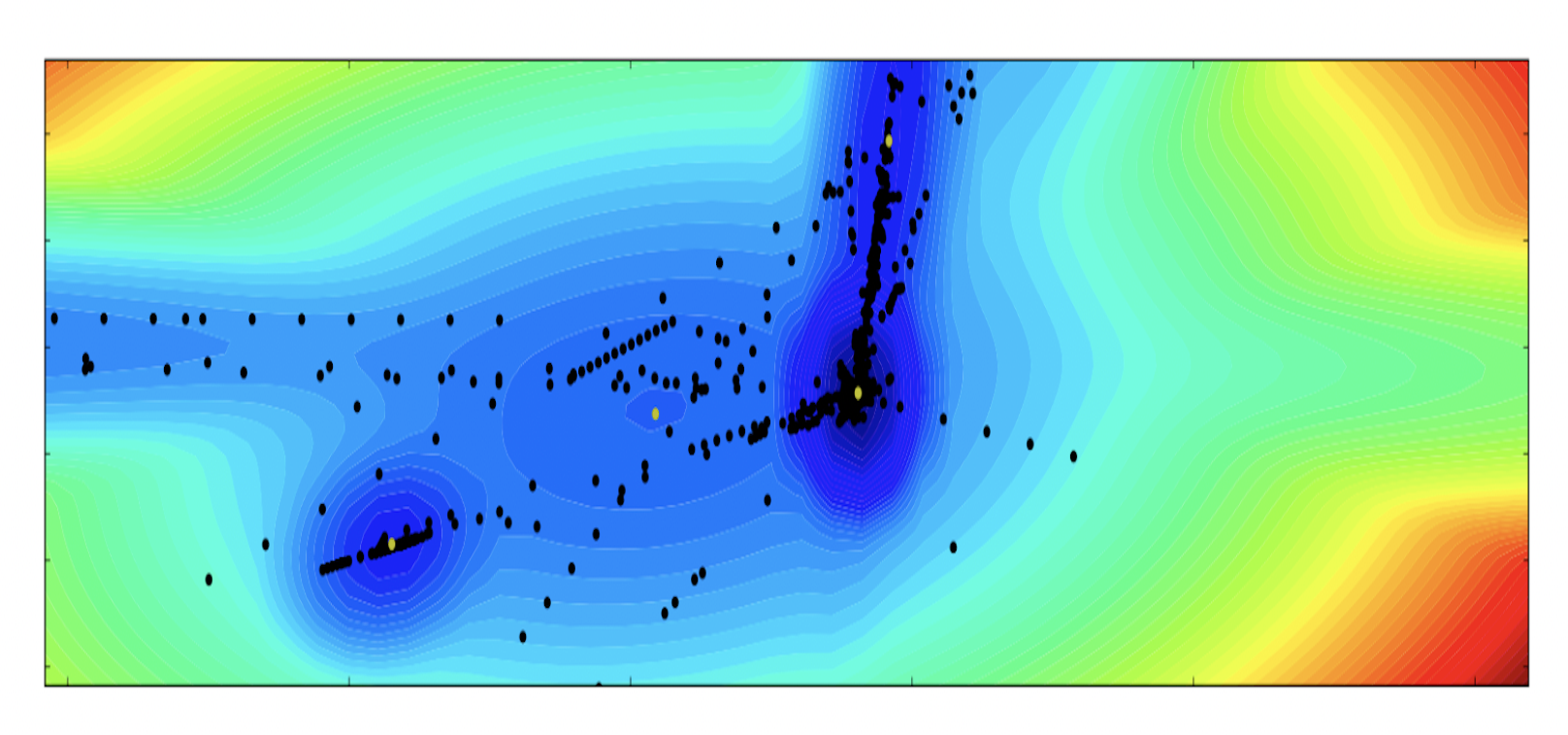 Predicting students’ happiness from physiology, phone, mobility, and behavioral dataNatasha Jaques , Sara Taylor , Asaph Azaria , Asma Ghandeharioun, Akane Sano , and Rosalind W PicardIn 2015 International Conference on Affective Computing and Intelligent Interaction (ACII) , 2015
Predicting students’ happiness from physiology, phone, mobility, and behavioral dataNatasha Jaques , Sara Taylor , Asaph Azaria , Asma Ghandeharioun, Akane Sano , and Rosalind W PicardIn 2015 International Conference on Affective Computing and Intelligent Interaction (ACII) , 2015In order to model students’ happiness, we apply machine learning methods to data collected from undergrad students monitored over the course of one month each. The data collected include physiological signals, location, smartphone logs, and survey responses to behavioral questions. Each day, participants reported their wellbeing on measures including stress, health, and happiness. Because of the relationship between happiness and depression, modeling happiness may help us to detect individuals who are at risk of depression and guide interventions to help them. We are also interested in how behavioral factors (such as sleep and social activity) affect happiness positively and negatively. A variety of machine learning and feature selection techniques are compared, including Gaussian Mixture Models and ensemble classification. We achieve 70% classification accuracy of self-reported happiness on held-out test data.

2013
- A data mining approach for diagnosis of coronary artery diseaseRoohallah Alizadehsani , Jafar Habibi , Mohammad Javad Hosseini , Hoda Mashayekhi , Reihane Boghrati , Asma Ghandeharioun, Behdad Bahadorian , and Zahra Alizadeh SaniComputer methods and programs in biomedicine, 2013
@article{alizadehsani2013data, title = {A data mining approach for diagnosis of coronary artery disease}, author = {Alizadehsani, Roohallah and Habibi, Jafar and Hosseini, Mohammad Javad and Mashayekhi, Hoda and Boghrati, Reihane and Ghandeharioun, Asma and Bahadorian, Behdad and Sani, Zahra Alizadeh}, journal = {Computer methods and programs in biomedicine}, volume = {111}, number = {1}, pages = {52--61}, year = {2013}, publisher = {Elsevier}, } - Diagnosing coronary artery disease via data mining algorithms by considering laboratory and echocardiography featuresRoohallah Alizadehsani , Jafar Habibi , Zahra Alizadeh Sani , Hoda Mashayekhi , Reihane Boghrati , Asma Ghandeharioun, Fahime Khozeimeh , and Fariba Alizadeh-SaniResearch in cardiovascular medicine, 2013
2012
- Diagnosis of coronary arteries stenosis using data miningRoohallah Alizadehsani , Jafar Habibi , Behdad Bahadorian , Hoda Mashayekhi , Asma Ghandeharioun, Reihane Boghrati , and Zahra Alizadeh SaniJournal of Medical Signals and Sensors, 2012
@article{alizadehsani2012diagnosis, title = {Diagnosis of coronary arteries stenosis using data mining}, author = {Alizadehsani, Roohallah and Habibi, Jafar and Bahadorian, Behdad and Mashayekhi, Hoda and Ghandeharioun, Asma and Boghrati, Reihane and Sani, Zahra Alizadeh}, journal = {Journal of Medical Signals and Sensors}, volume = {2}, number = {3}, pages = {153--159}, year = {2012}, publisher = {Medknow}, } - Diagnosis of coronary artery disease using cost-sensitive algorithmsRoohallah Alizadehsani , Mohammad Javad Hosseini , Zahra Alizadeh Sani , Asma Ghandeharioun, and Reihane BoghratiIn 2012 IEEE 12th International Conference on Data Mining Workshops (ICDM) , 2012
- Diagnosis of coronary artery disease using data mining based on lab data and echo featuresRoohallah Alizadehsani , Jafar Habibi , Zahra Alizadeh Sani , Hoda Mashayekhi , Reihane Boghrati , Asma Ghandeharioun, and Behdad BahadorianJournal of Medical and Bioengineering, 2012
- Exerting cost-sensitive and feature creation algorithms for coronary artery disease diagnosisRoohallah Alizadehsani , Mohammad Javad Hosseini , Reihane Boghrati , Asma Ghandeharioun, Fahime Khozeimeh , and Zahra Alizadeh SaniInternational Journal of Knowledge Discovery in Bioinformatics (IJKDB), 2012